

Everyone is Doing Keyword Research Wrong. Here’s the Right Way
In the site building world, people generally overthink everything. It’s true for pretty much every element of the game — link building, monetization, and so on — except one…
Keyword research.
Keyword research might be the only sub-discipline of site building that people underthink.
And that’s baffling. Keyword research is perhaps the most foundational core competency in SEO. If you don’t do good keyword research, you don’t get a return on any of your other activities (not to mention your money).
But there’s a tendency among independent SEOs to boil keyword research down to one metric: keyword difficulty (KD). People plug some seed keywords into a tool, filter by KD, grab any keyword below a certain threshold, and start ordering content.
This is wrong.
Looking at only the KD and search volume of single keywords ignores the way Google actually treats content.
One keyword almost never makes or breaks an article. When articles win, it’s not because they ranked well for a single keyword; it’s because they rank for hundreds or thousands of keywords.
In short, good content captures the “long tail.”
If the most successful content is the content that best captures the long tail, why are we still obsessed with single keywords?
I contend that we should forget single keywords. Instead, we should learn how to understand what the long tail looks like for entire topics — and then create articles that capture as much of that as possible.
This isn’t easy.
In fact, it’s pretty hard. For some topics, there might not even be a long tail. For others, the KD of important keywords may be skewed (I’ll show you how), or the pages capturing the long tail may be doing it in a way you can’t compete with.
So just visualizing the long tail of a topic takes a certain savvy. But if you do…
If you can understand and visualize the long tail for low-competition topics in your niche, you the profitability of your keyword research can compound exponentially.
This isn’t new…
This concept is called topical keyword research.
And I’ll be the first to say it: it’s nothing new.
Plenty of people have talked about topical keyword research before I wrote this post. Some have even said keyword research is dead (it’s not). So I’m certainly not the first to write about it.
But there’s a glaring problem with the information currently available: people have mostly only discussed topical keyword research in theoretical terms. And that’s great; the theory is important and provides a vital context.
But we still need to do actual research and plan our actual content strategy.
You can have all the theory in the world, but it doesn’t mean much if no one has shown anyone else exactly how to do it. To be frank, I’m not sure anyone even has a good, data-driven system for topical keyword research (there are some how-tos out there, but they tend to be either superficial or are mostly willy nilly-style tactics that are not driven by real data).
That’s what I want to provide here.
Today, I want to show you the keyword research methodology I developed to (1) find topics for which there is massive, low-competition long tail and (2) write content that ranks for as much of the long tail as possible.
Before we do that, I want to quickly recap the “old way” of doing keyword research — mostly for context but also because we will be using parts of it in our new method.
The “old way” of doing keyword research (and why it’s suboptimal…)
Site builders have come up with lots of ways to find good keywords over the years, but nowadays, most break them into two types:
- Seed keyword research
- Competitor keyword research
Let’s do a super quick overview of each.
An Overview of Old-School Seed Keyword Research
Quick note: For the purposes of our article and because I think it’s the best tool on the market, we’ll use Ahrefs to demonstrate.
Seed keyword research relies on using the keyword difficulty scores of tools like Ahrefs or KW Finder.
“Seed keywords” refer to the keywords you input in order to generate lists of related keywords you can then sort and filter.
In Ahrefs, you’d start with the Keyword Explorer and type in a seed keyword.
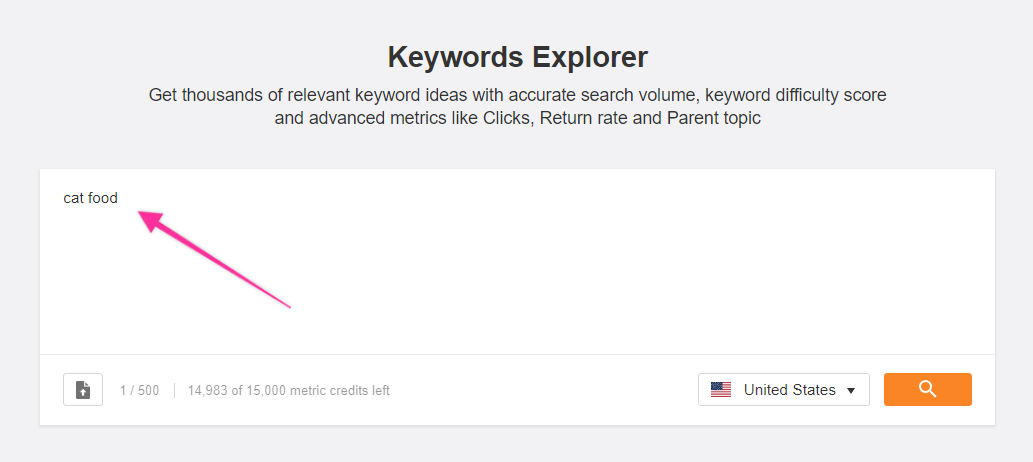
You’ll get a screen that looks like this, which will tell you the keyword difficulty score of that specific keyword.

To find other, related keywords, you’d click All to see a big list of keywords Ahrefs thinks are related.

Then, you could use filters to find keywords with good buying intent, low difficulty, and relatively good volume.
Here, for example, you could filter to find keywords that include the word “review” and set parameters for KD and search volume values.
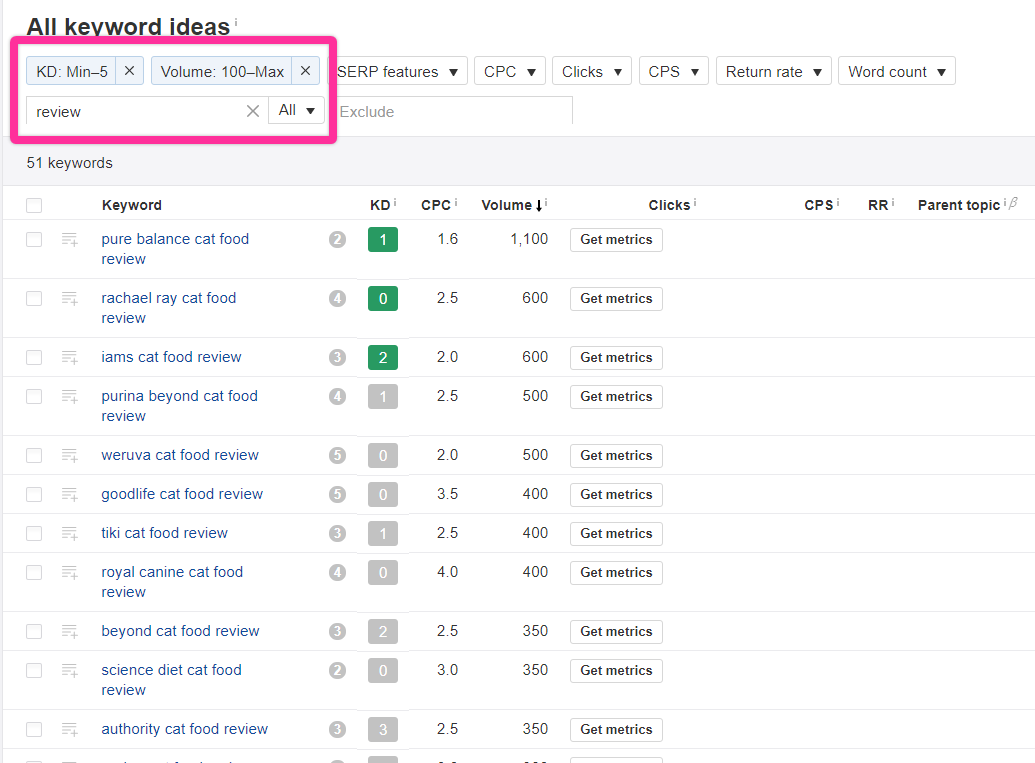
This is about where most people stop.
They pick some keywords out of this list — likely the ones with the lowest KD — and just… start writing about them.
Don’t get me wrong: seed keyword research is a good way to find keywords. In the current landscape of SEO, it’s simply incomplete.
The Problem with Old-School Seed Keyword Research
Even though some of these keywords might be easy to rank for, they may not have an adequate long tail to be profitable. Or they might have a huge long tail that we just aren’t targeting.
And that’s the problem: with this keyword research method, there’s just no way to tell what’s going on in the long tail.
There’s also has one other serious drawback: it assumes each piece of content you produce will only be about one topic and doesn’t consider that a single page can rank well for several.
Seed keyword research definitely has its place. It’s just not enough.
An Overview of Old-School Competitor Keyword Research
Typical competitor keyword research aims to find and compete with your competitors’ best keywords.
You use a competitor analysis tool to see which keywords drive the most traffic, and then you write some content that competes for those same keywords.
In Ahrefs, we’d plug in some competitor — usually one that as a domain rating (Ahref’s authority metric) close to our own.
For this example, let’s assume we’ve got a pretty authoritative fitness site, and we’re looking for keywords in the running shoe space.
We might head over to Ahrefs’ site explorer tool and plug in a competitor like RunnerClick, a well-known affiliate site in the market.
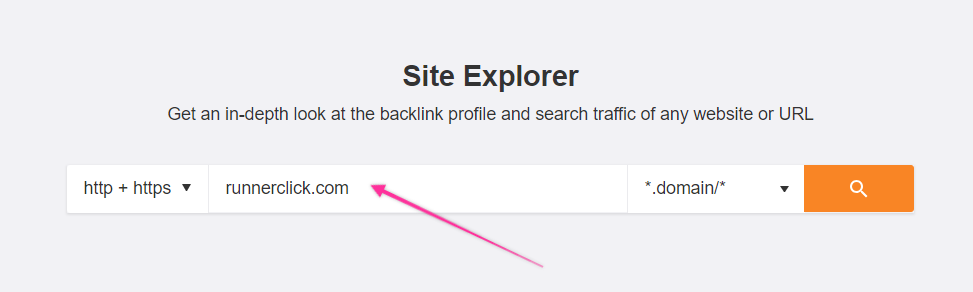
You’d then see the overview screen for RunnerClick.
From there, you’d click Organic Keywords in the left sidebar, which takes you to a list of their keywords, sorted by default to show you those that drive the most traffic.
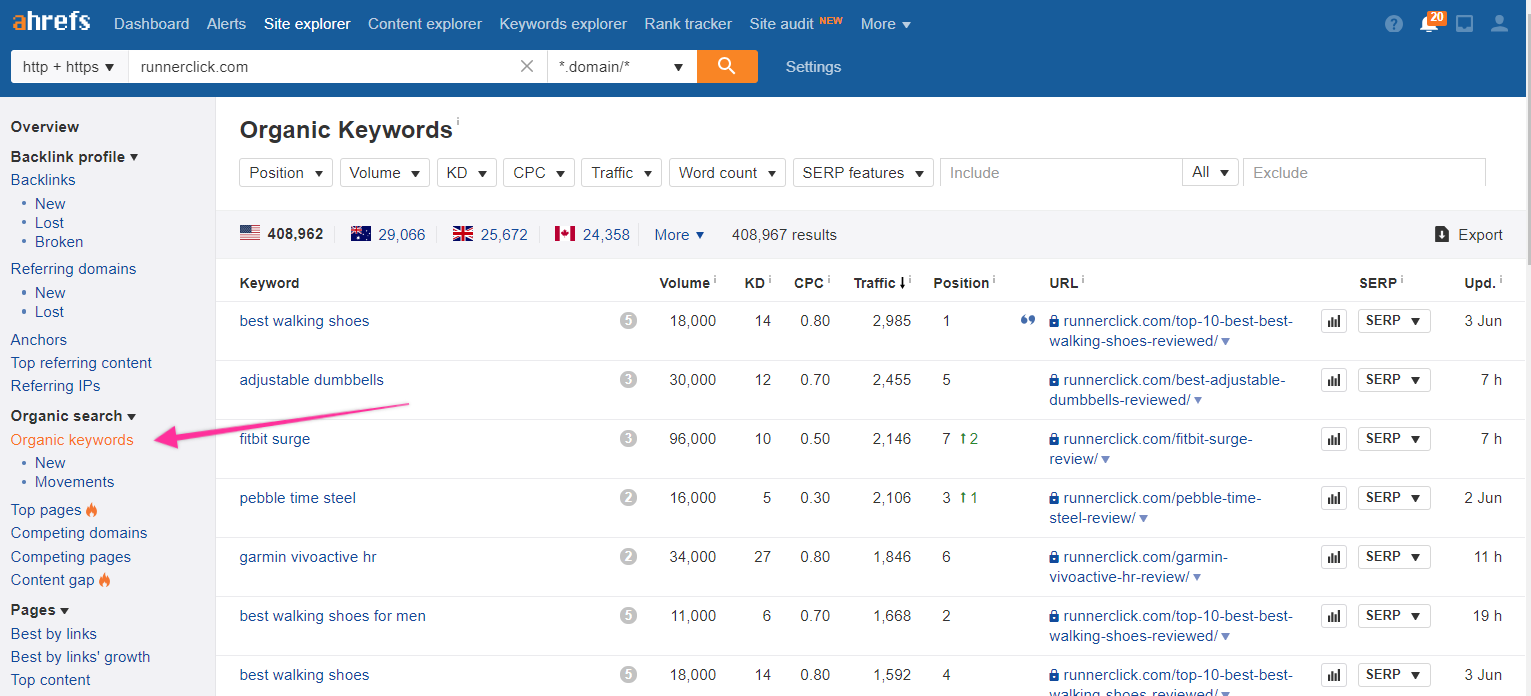
You could sort by KD here as well, which would help you find low-competition keywords RunnerClick ranks for, again, sorted by traffic yield.
Or, if you were authoritative enough (or had money to spend), you could simply look at their best keywords and try to compete for them.
That’s the basic process, anyway.
You could do the same for another competitor. And another. And so on until you had a bunch of great keywords.
Simple, right?
Well, sure. But it’s still not enough.
The Fatal Assumption of Old-School Competitor Keyword Research
Aside from leaning too heavily on single keywords, which has all the same drawbacks as other old-school methods, traditional competitor keyword research only considers one competitor at a time, which means if we create competing content, it can only do as well as one of our competitor’s pages.
That’s limiting because no competitor covers 100% of any topic. We need a method with a wider scope — something that allows us to see and understand not just the keywords one of our competitors ranks for, but where multiple competitors overlap.
That’s how you create truly comprehensive content that can compete in all areas of a topic.
The good news?
There’s a better way. A more efficient way. A way to leverage the power of the long tail to evolve beyond single keywords and start crafting content with extreme traffic potential — even if they’re hidden or look bad on paper.
Let’s talk about it.
New-School Topical Keyword Research: A Bird’s Eye View
If old-school keyword research was about locating keywords with the lowest-possible keyword difficulty, new-school topical keyword research is about one thing: estimating traffic potential.
That absolutely does not mean we should be going after only high traffic keywords.
On the contrary: all the same old guidelines of keyword research still hold true:
- We want to find low-competition keywords
- We’ll be happy to target keywords with low search volume
- …and so on…
What changes here will be the context.
Namely: (1) instead of looking at single keywords, we’ll be analyzing groups of keywords (i.e. topics), and (2) instead of looking at search volume, we’ll be looking at both the length of the “long tail” and the traffic of our competitors.
Thus, in order to do new-school topical keyword research, we need to be able to do three things:
- Estimate the overall difficulty of a whole topic
- Estimate the length of the “long tail”
- Use competitor traffic data to estimate traffic potential
Each of these serves a different purpose.
- Estimating the difficulty of a topic will help us understand how easily we can rank for the keywords that make up that topic.
- Estimating the “long tail” will help us understand how many keywords make up the topic (and therefore how many opportunities we have to rank).
- And estimating traffic potential will help us understand the potential return on our investment.
As you can probably see, compared to old-school keyword research, this is vastly more complicated.
But it’s also vastly more powerful.
The main benefit is that you can drastically increase traffic per article. This is a screenshot of one of my new projects this year. The site only has 30 articles (only about 20 of which are meant to attract organic traffic; the rest are used for link building) and relatively few links, but it generates nearly 30,000 visits per month.
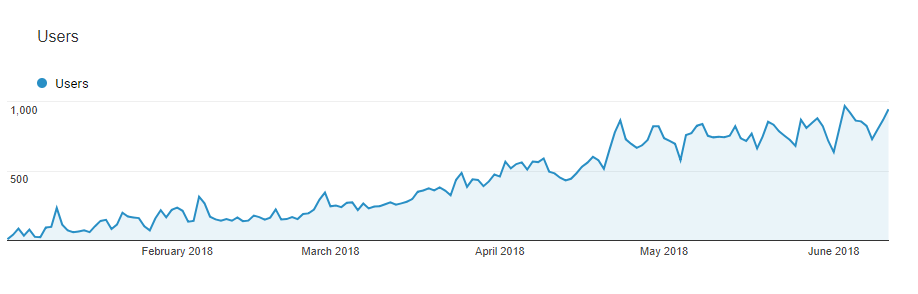
On average, each of those articles pulls in over 1,000 visits per month, which is very strong for a new(ish) site that’s so small.
I’ve seen similar results across other sites. It works. Doing keyword research this way can generate great traffic with fewer articles.
And it’s honestly not rocket science. You just need to expand the keyword research knowledge you probably already have.
Before we do anything we need to find some kind of starting point — a topic we can dig into, so we can actually look at the topical difficulty, long tail, and traffic potential. To do this, we can use a very familiar skill.
Finding a Starting Point
To find a starting point, we can use either traditional seed keyword research or traditional competitor keyword research (the exact same processes outlined above).
The idea is to use those tactics to find keywords that indicate large topics behind them.
Let’s run through an example.
Suppose I had a home improvement site, and I wanted to add some content on power tools. I might brainstorm a list of power tools and use those as seed keywords to generate a big list of related keywords.
Just to make my life easier, I might even go find a list of power tools and plug those in.

Then, I could plug these into Ahrefs.
After searching, I’d apply filters for modifiers I know indicate good buying intent, since those keywords tend to convert really well on affiliate sites. Stuff like “best” and “reviews.”
I’d also include KD filters. We’re not looking for single keywords — and we eventually want to estimate the difficulty of entire topics — but lower-difficulty keywords certainly do tend to belong to lower-difficulty topics.
With filters applied, a list might look something like this:
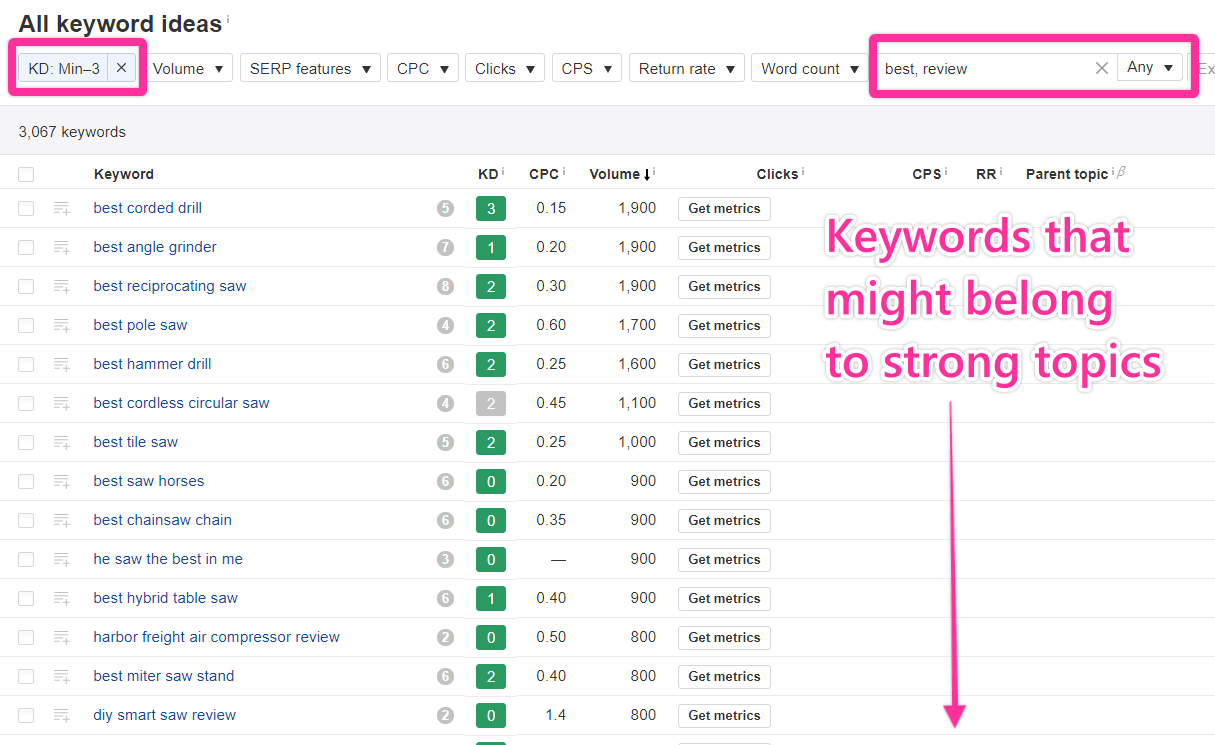
That is a lot of topics to investigate.
And honestly, you wouldn’t be messing anything up by just grabbing these and writing about them. But…
…you also wouldn’t be maximizing your traffic potential to the absurd levels that might be possible. To do that, you’ve got to analyze whole topics.
Let’s start by rethinking keyword difficulty.
How to Estimate the Keyword Difficulty of a Topic (…not just one keyword)
I usually define “topic” as a group of tightly related keywords.
To calculate the keyword difficulty of a topic, then, you just have to look at the average difficulty of tightly related keywords.
In practical terms, where can we look at a whole topic?
We can use Ahrefs.
We have to be very careful when we do this, though, because there are lots of features inside Ahrefs that look like they could help us look at the keyword difficulty of a bunch of keywords in a topic but could actually hurt our keyword research.
I want to point them out first, so you can avoid them.
The main culprit is the “Also rank for” tool. When I was developing topical keyword research tactics and wanted to get an overview of a whole topic, I found myself drawn to this feature. It definitely seemed right. It’s not.
We do not want to use the “Also rank for” function (this one):
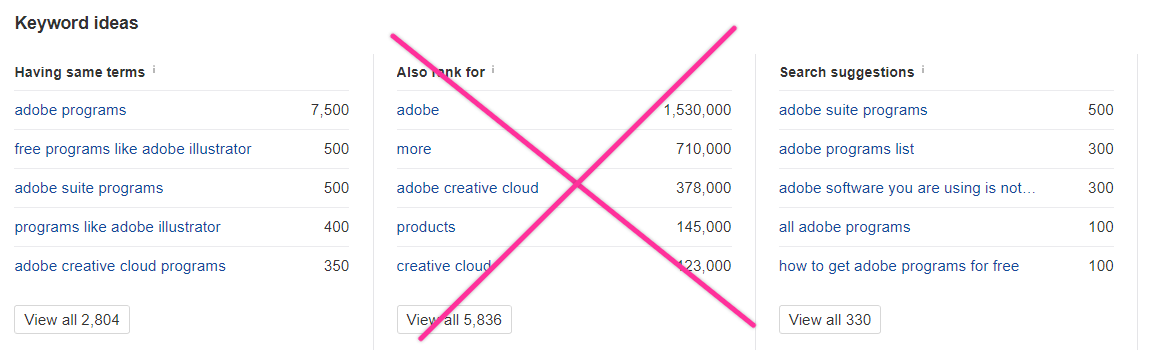
Here’s why.
The “Also rank for” report does, in fact, show you all the keywords winning pages also rank for. But, crucially, it organizes them by volume and has no traffic data.
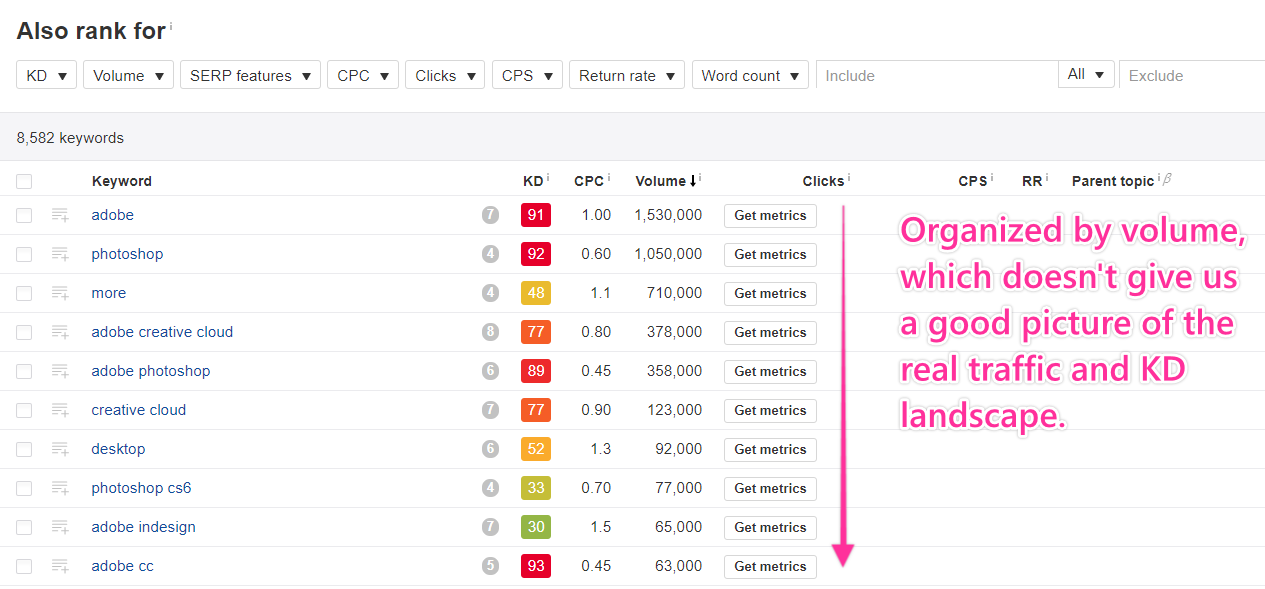
This shows us the biggest keywords.
It does not show us the most valuable keywords (the ones driving traffic).
It’s even more dangerous that this report omits traffic or position data for these gigantic keywords. For all we know, winning pages could be ranking on page 10.
We don’t need that. We need a bird’s eye view of the keywords that actually generate traffic for the pages ranking for our main keyword.
A much better way to do that is to open up keyword reports for competitor pages most like our own.
We can start by looking at the SERPs for any keyword we think we might want to go for.
Let’s pretend we have a software affiliate site, and we’re searching for “best adobe software.” After typing it into the Ahrefs Keyword Explorer tool, the SERP will be at the bottom of the page.
We can view keyword reports by clicking the dropdown arrow next to the URL in Ahref’s SERP analysis and then clicking “organic keywords.”
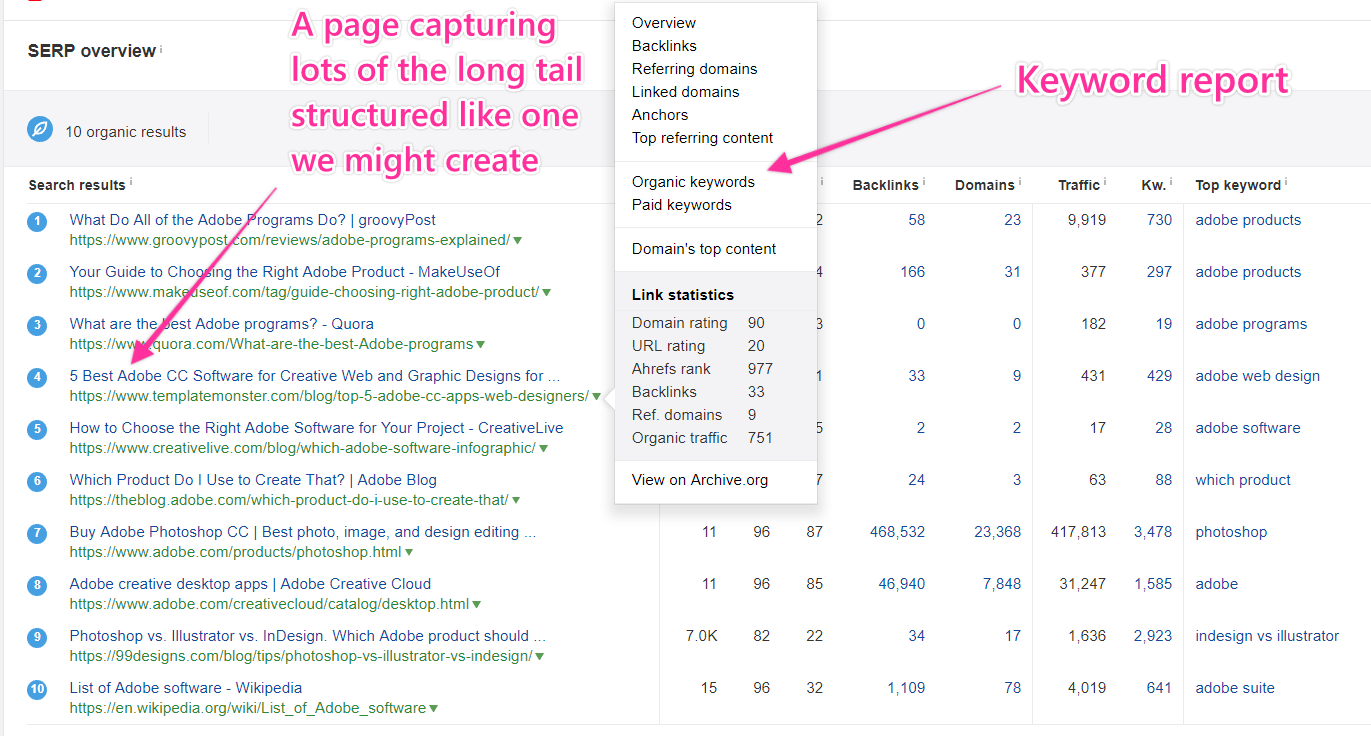
That will take us to a report of all the keywords that page ranks for, but instead of being organized by volume, it’s organized by traffic yield.
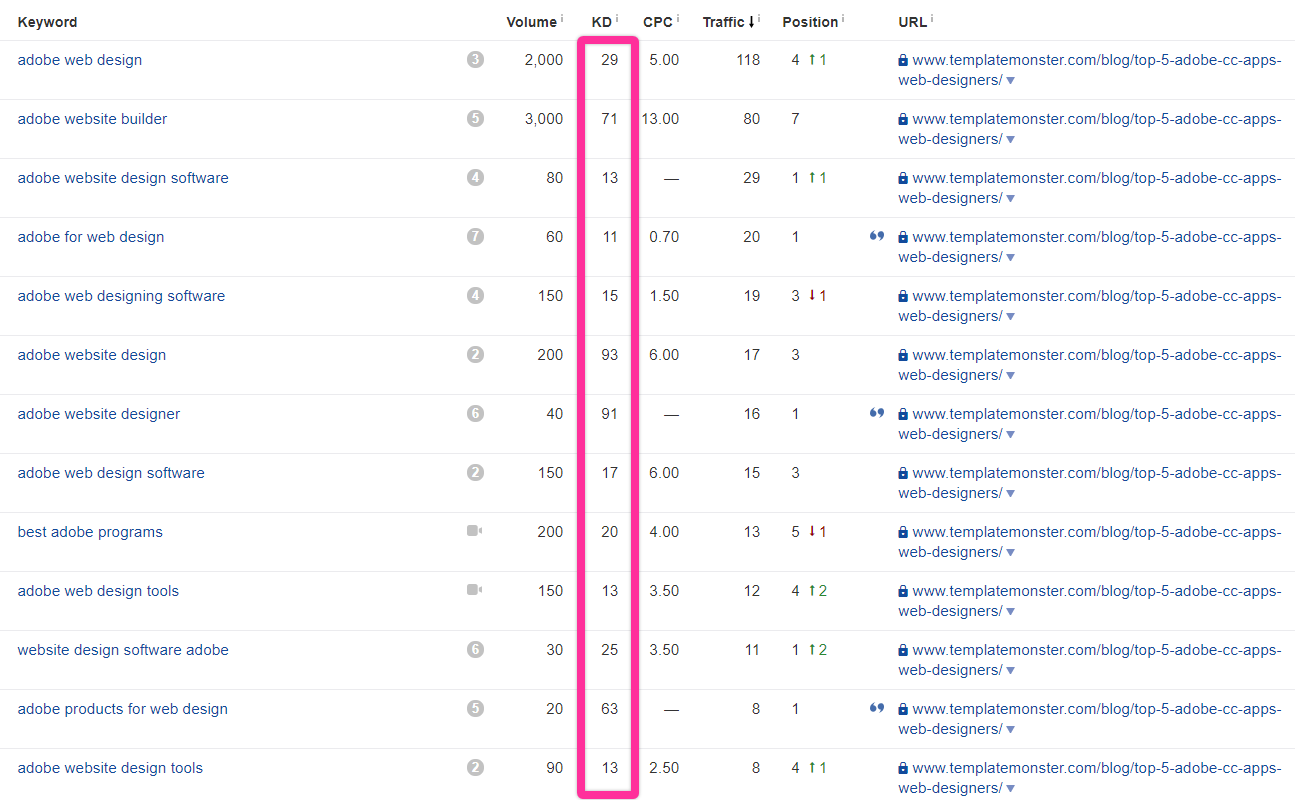
This is a much clearer picture of an overall topic and its subtopics.
To get a really accurate picture, of course, we need to look at similar reports for multiple competitors who are creating content like ours. But even peeking at one can give you a good idea of the topical keyword landscape.
Because here, we get to see the long tail in action. It’s not just the big keywords that generate traffic; it’s the amalgamation of everything in the long tail.
Let’s dig into this example to demonstrate.
In the page above, we see that it ranks for a couple very high profile keywords, but over half of the top keywords are under KD 20.
This is a good sign. We can see pretty clearly that a good chunk of the keywords this page ranks for are actually lower than the KD of the main keyword we found (“best adobe software”).
There’s also a hidden gem in that list. Did you see it?
It’s “best adobe programs,” which has nearly the same search volume as the main keyword we found but has a lower KD and higher search volume. We could potentially optimize our page for this specific keyword and eek out a bit more traffic.
To get a feel for the overall difficulty of the topic, we’d look at the reports for all our closest competitors in the SERPs.
So the process of estimating topical KD might look something like:
- Find competitors who are ranking well for a keyword you might want to go for with pages like the one you might create
- Open their keyword reports
- Get a feel for the general KD range for that topic
So, there is no exact formula.
The process is much more about surveying the land.
We don’t need to calculate the averages of anything here. We just need to look at the keywords that are driving real traffic to competitor pages and get a rough idea of how difficult this topic is relative to the keyword we found.
How to Estimate the Length of the “Long Tail”
I define the “long tail” as the number of keywords available for a topic.
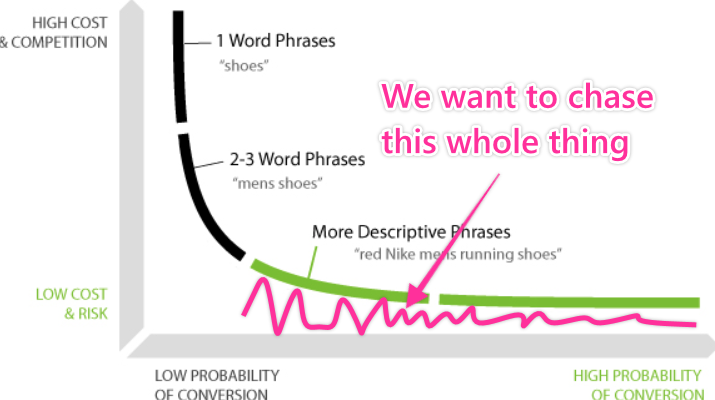
The concept of the long tail has been around for a long time. When people talk about it, they usually use a diagram, like this one (from Neil Patel):
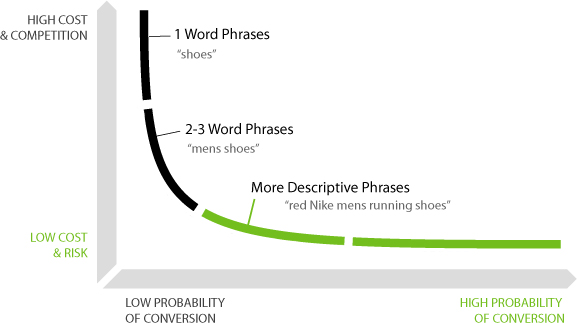
In old-school keyword research, you’d pick one of those “long tail” keywords and try to rank for it.
The idea behind new-school topical keyword research is to not only try to rank for one long tail keyword, but many. We can do this because most of the time, the keywords that make up the long tail of any topic are closely related to one another.
However, because we’re making a play for the entire long tail of a topic and not just one keyword, we want to pick topics with big, healthy long tails.
Why? Because the bigger the long tail, the more opportunities we have to rank.
If a topic has a short long tail, for example, successful articles covering that topic might only rank for a few dozen keywords. On the other hand, if a topic has a really long long tail, a successful article might rank for thousands of keywords.
Why is this important?
Why don’t we just look at overall traffic potential?
Traffic potential is also very important. They’re just different metrics. Traffic potential is about, well traffic.
The long tail is about estimating your risk by maximizing your number of opportunities.
Here’s another way to look at it: all things being equal, it’s better (and safer) to have a shot at 5,000 different related keywords than 100. Even if our article misses the 20 juiciest keywords, we could still potentially capture the other 4,980.
Of course, that’s not usually how it works.
Articles that rank for some keywords are much more likely to rank for others, but even if you only rank for a tiny percentage of the available keywords for a topic, it’s better to rank for a tiny percentage of 5,000 and 100.
The other benefit of a big long tail is that it often means you can invest more into a single piece of content.
How long is long?
The short and perennially annoying answer is: it depends.
It depends on the niche, search volume, and value of the topic. Larger search volumes and higher traffic value (based on something like revenue per visitor) give you a bit more leeway with the long tail.
If you’re in the VPN space, for example, small amounts of traffic can be incredibly valuable, which means you don’t necessarily need as high of a long tail threshold.
Still, longer is better.
As a general rule, for most niches, I like to see a long tail of at least a couple hundred keywords. And if I see a long tail in the thousands, I start to get really excited, especially if the KDs for the main keywords are low.
Okay. Awesome. But where do you see it? How do you even estimate it?
All the data is right there in Ahrefs. Let’s look at couple keywords.
Suppose we were starting a lawn care site and wanted to review lawn mowers. In our research, we came across the keyword “best mower for hills.”
The KD is very low, which is good.
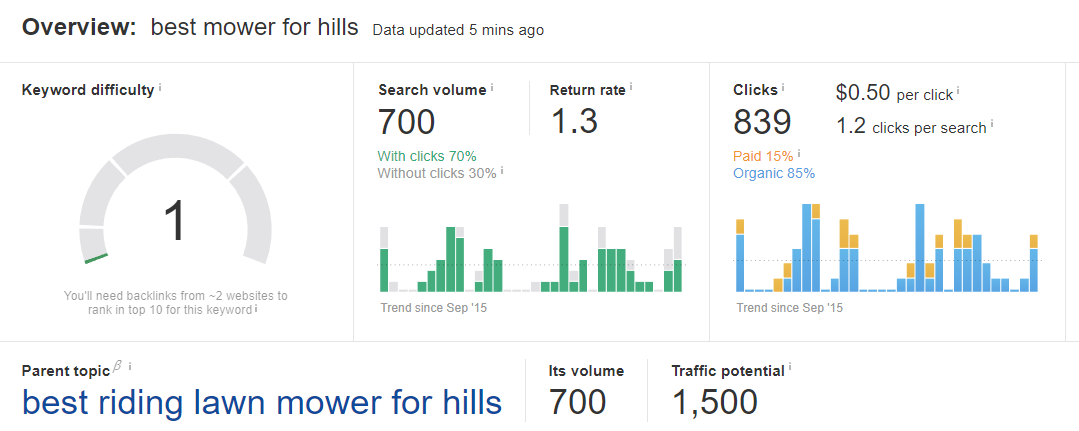
But how’s the long tail?
If we scroll down a bit on the Ahrefs page, we can dig into the SERPs and see.
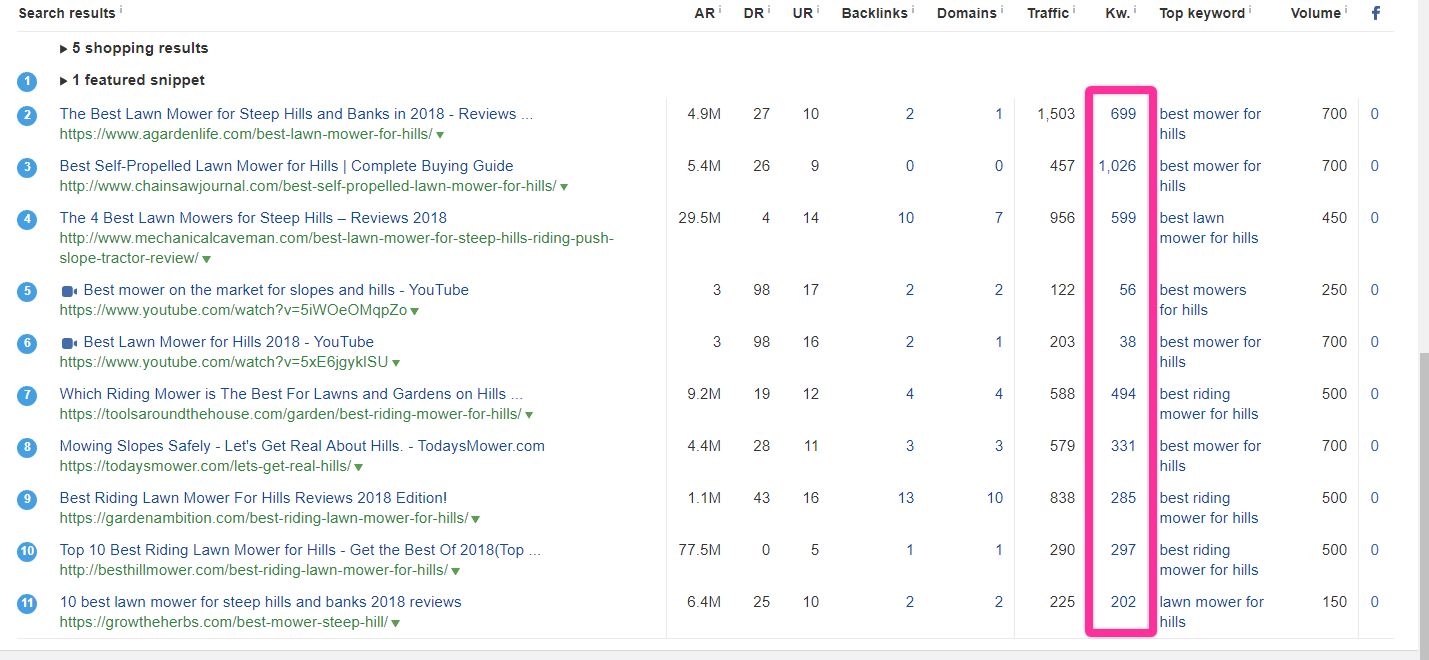
Almost all pages ranking in the SERPs for this keyword also rank for several hundred related keywords, and it’s even more encouraging that they appear to do so with relatively few links.
There are a few results (in spots #5 and #6) that don’t capture much of the long tail, but those are both YouTube videos, which aren’t content-rich pages.
If we wanted to dig a bit deeper, we could click through to a couple of results. For example, this is the page from the site ranking in the #1 spot, A Garden Life, which, aside from ranking well for the main keyword, also ranks for nearly 700 other keywords.
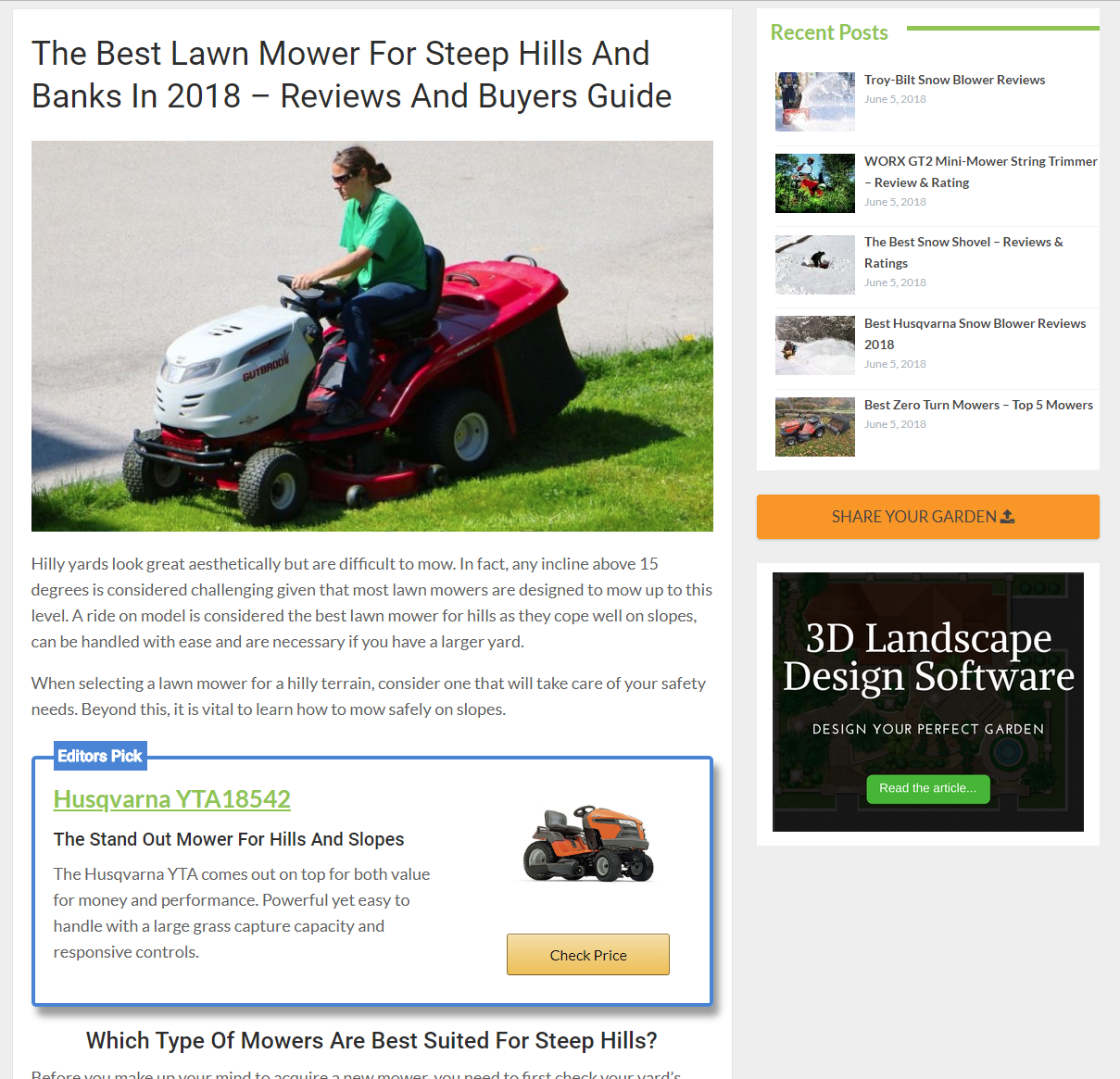
It’s a relatively standard Amazon affiliate page. That’s a great sign because that’s the kind of site we want to create.
Let’s see what keywords this specific page is looking for by plugging the URL into Ahrefs and looking at those 700 keywords.
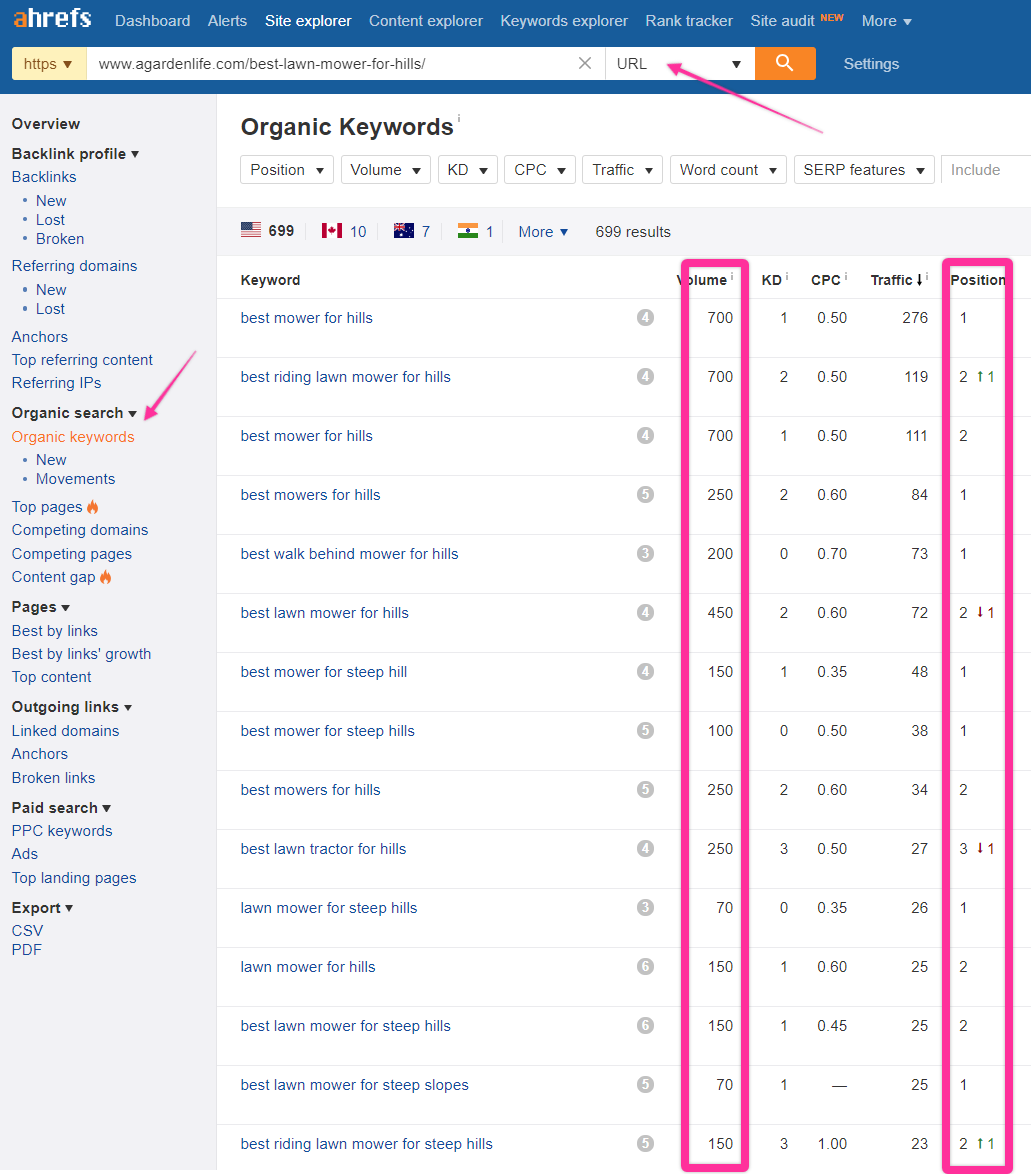
A couple of interesting things here.
First and most importantly, there are tons of variations of the same keyword. Pretty much everything we see here is some variation of the “best mowers for hills.” Additionally, all these variations each have hundreds of searches per month.
This tells us the search volume of the main keyword is deceptively low.
There aren’t 700 people looking for a mower that can handle hills; there are many thousands of people looking for one.
Secondly, we can see this page ranks in the top one or two spots for almost every keyword on this list. This could just be because Ahrefs sorts keywords by traffic, but it’s still fairly rare to see a page ranking 1-2 for every single variation.
This could indicate that if you rank for one of the main keywords, you’ll likely rank very well for many of them.
From a business perspective, that gives us a license to invest a lot more resources into this piece of content than we otherwise might.
And remember: there was one page in the SERPs that was ranking for more keywords than this one…
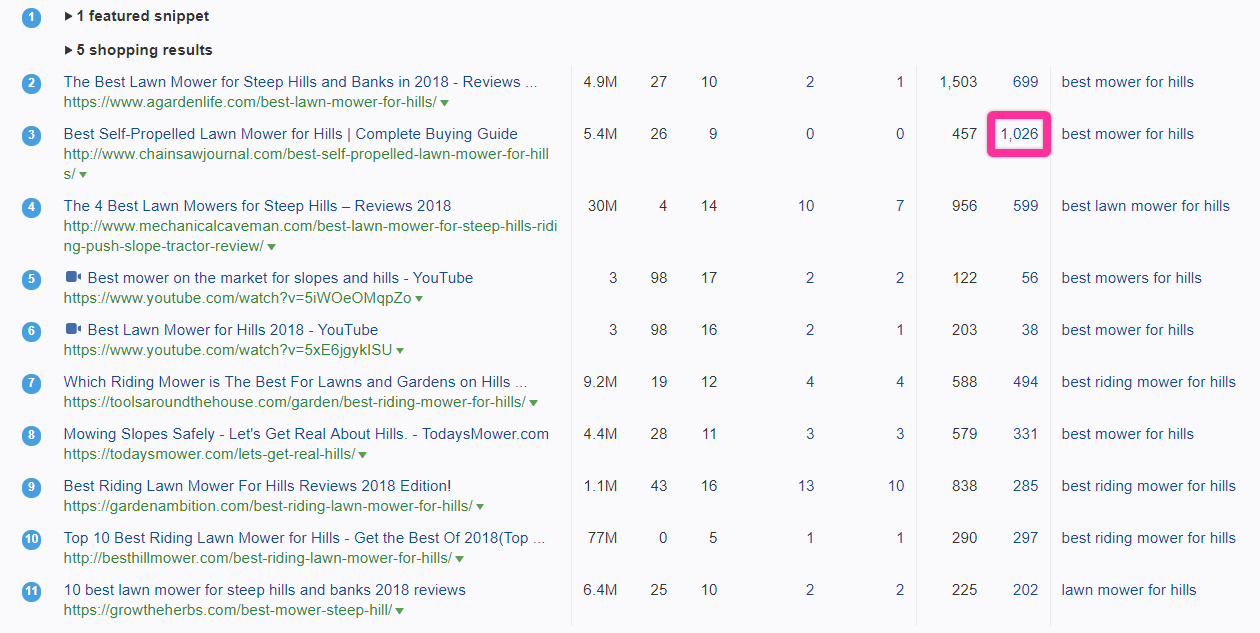
There are likely over 1,000 keywords available, especially if we take every set of keywords that every page ranks for and overlap them to see track all common keywords (we can do a version of this easily with content gap analysis, and I’ll show you how below).
Overall, if we were doing keyword research and looking for keywords with nice, big long tails, this would be more or less ideal.
How to Use Competitor Traffic to Estimate Traffic Potential
When estimating the traffic potential of a topic, maybe the most relevant data point we have is competitor traffic.
In fact, competitor traffic can sometimes even override our other metrics (KD and long tail length).
The reason, I hope, is obvious: if competitor pages generate lots of traffic, we probably have a better chance of generating traffic with a competing page of our own.
And, of course, the more traffic we see floating around, the better. So if we see competitors getting lots of traffic, we’ll be more likely get lots of traffic of our own.
There are, of course, some nuances.
In some SERPs, for example, the results will be obvious: all the ranking pages will capture good amounts of traffic.
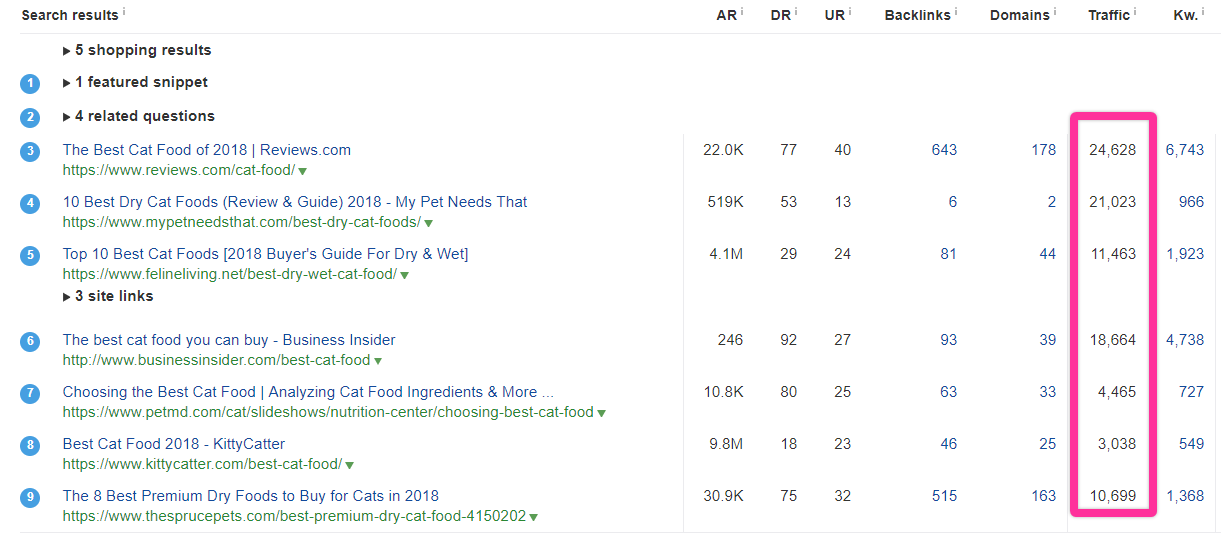
Here’s the SERP for “best cat food.”
Pretty much everyone ranking for this keyword is capturing a good chunk of the long tail and is generating lots of great traffic.
Others, however, won’t be as clear. What if you see a result like this one…
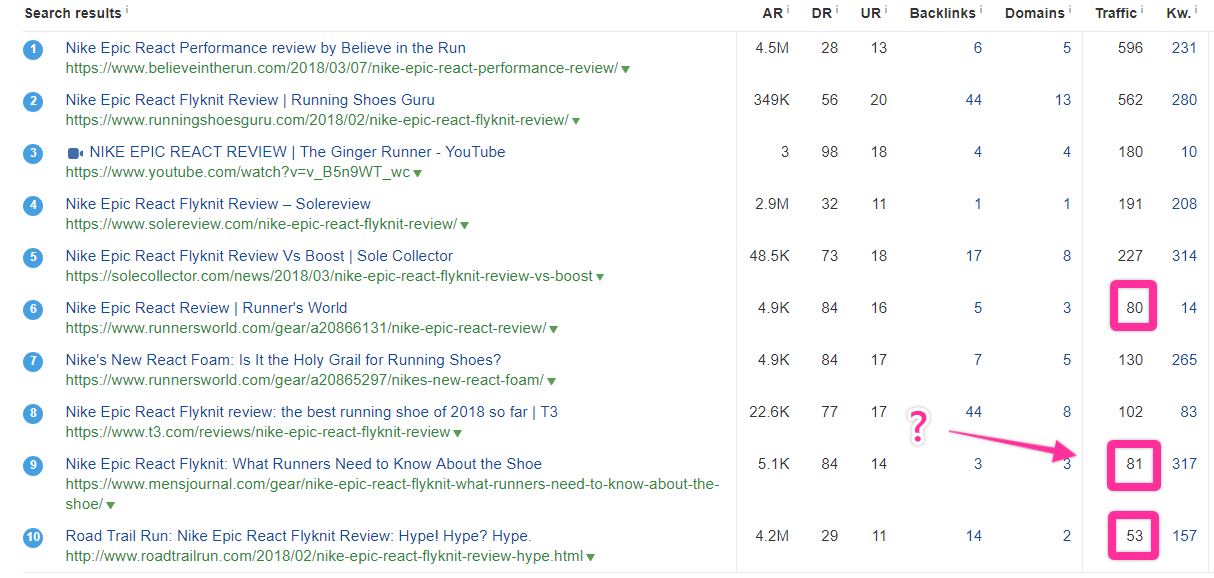
This is the SERP for “nike epic react review,” and it’s significantly less straightforward.
There are definitely some pages generating decent traffic, especially toward the top, but there are also pages in the top 10 that don’t seem to be generating much traffic at all.
As a keyword, “nike epic react review” has a search volume of 600, and the long tail is at least several hundred keywords long.
Here, some pages don’t have much traffic at all, but a few of the results do seem to be capturing lots of traffic.
Is this keyword good?
In cases like these, we typically don’t know unless we get our hands dirty.
We have to click through to the actual pages ranking, trying to identify patterns between the pages bringing in lots of traffic and those ranking in the top 10 for a specific keyword but falling short on overall traffic.
We’re looking for two main things:
- We want to make sure we can compete with the winning pages, and
- We ideally want to see obvious deficiencies in subpar pages
Of those two things, the first (that we can compete with winning pages) is by far the most important. Why? It’s our proof of concept. It’s the evidence that pages like ours can do well.
In fact, seeing even one page we can compete with is sometimes sufficient enough evidence to invest in a piece of content.
In our “nike epic react review” example, the page in the number one spot — and the page with the highest traffic overall — is a page from Believe in the Run, a site with relatively little authority (DR28, something most independent site builders could achieve in under a year).
It’s also a short piece of content (under 1,000 words) and doesn’t have many links (five referring domains).
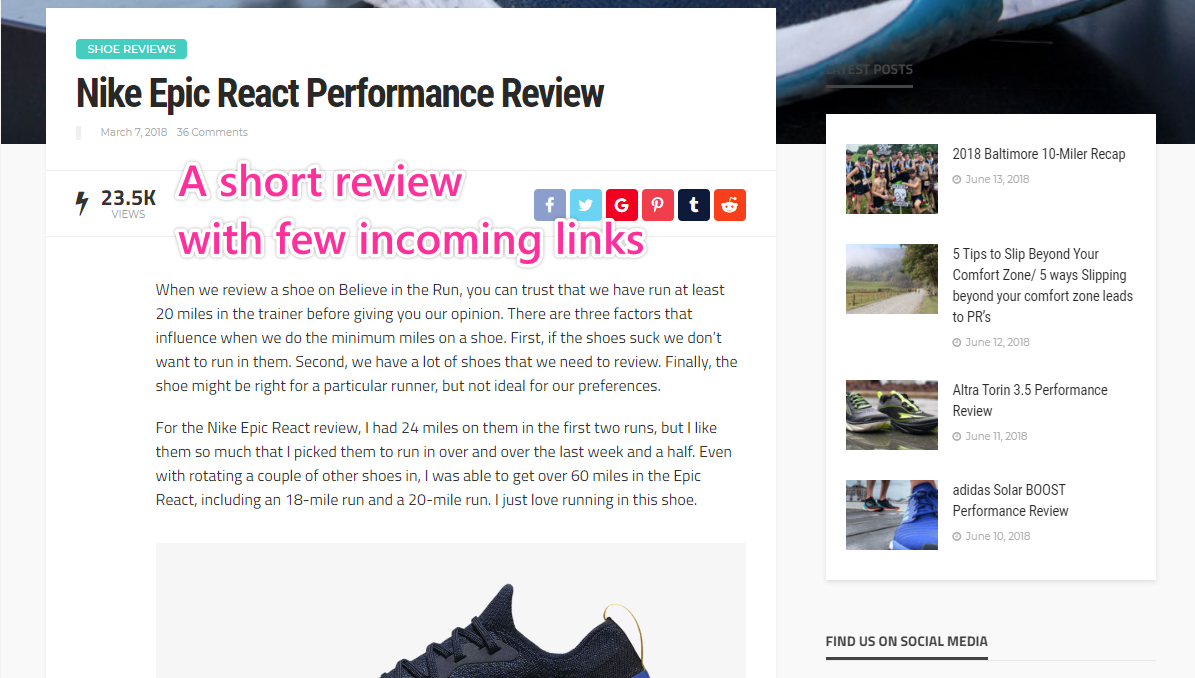
The content itself would be easy to beat, at least in terms of length. We could easily replicate it and improve on it.
The 5 referring domains weren’t all that impressive: a dead site, a 2.0 link, a blog comment, a dead tag archive, and a nofollow link. This more or less amounts to zero real links.
All of this together — the low domain authority, beatable content, and low inbound links — would drastically boost my confidence that I could compete with this page, hopefully capturing similar traffic.
And what about the subpar pages?
It’s not as important to determine why subpar pages aren’t doing well. But ideally, there will be easy answers. For example, in the SERP above, one of the pages has no content on it for some reason:
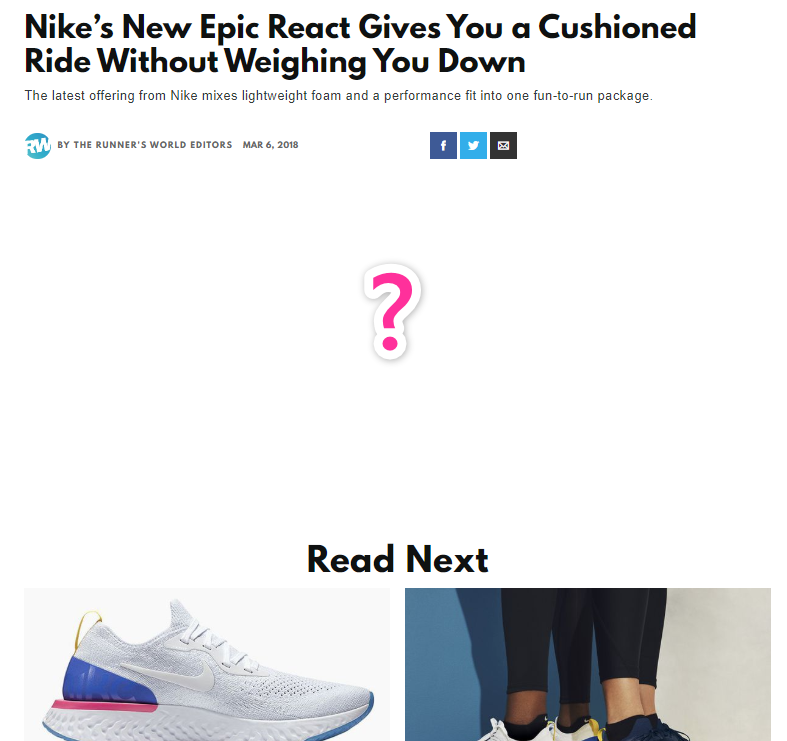
Because the keyword (or a version of it) appears in the title and URL — and likely because it’s on an authoritative domain — the page ranks for a few highly relevant keywords; however, because there’s no actual content on the page, it doesn’t rank for much else.
Not all subpar pages will have obvious answers like this. And finding clear deficiencies isn’t required.
But if you do, you can interpret it as risk reduction (i.e. the missing traffic has some reason).
But how much traffic is good?
This is going to be annoying, but it depends.
First, It depends on the RPMs (revenue per thousand visitors) you expect to generate with your site.
If you’re planning on monetizing with, say, display ads, you know the RPMs are generally pretty low, which means you’ll need a lot more traffic.
If, on the other hand, you’re reviewing hosting services, you probably know those companies have ridiculous commissions, and your RPM will be much, much higher.
Second, it depends on your resources. If you have lots of resources and can afford to earn slower returns, it’s more feasible to target lower-traffic topics.
Most of us, though, don’t have tons of money to throw around, so we need to be picky with the topics we choose to write about at first. Because we might only be able to afford 30 or 40 articles, it makes sense to take greater care to find topics with the highest possible traffic yield.
Lastly, it depends on your skills. The site builder starting their very first project may settle for slightly lower traffic potential in favor of extremely low difficulty, which makes sense; it reduces risk, and it’s typically more important for these folks to make any money than to enter into the more finicky risk-reward of higher competition SEO.
Experienced site builders, however, might be better equipped to compete with higher-authority pages, which means they can sacrifice a bit of risk reduction for a higher profit ceiling.
Beware: sometimes traffic is deceptive…
One last note here.
Sometimes traffic can be deceptive. Sometimes, you’ll find a low-competition keyword, and the ranking pages will just be rolling in traffic.
And sometimes those opportunities are legit (there are plenty of profitable topics out there). But other times, those traffic numbers will be a big fat lie.
This occurs when a page ranks for that small, low-KD keyword but gets most of its traffic from bigger “parent” keywords.
I call this the parent trap (no pun intended).
Let’s take a look at an example using one of the keywords we used earlier: “best adobe software.”
For “best adobe software,” Ahrefs lists the parent topic as “adobe programs.”
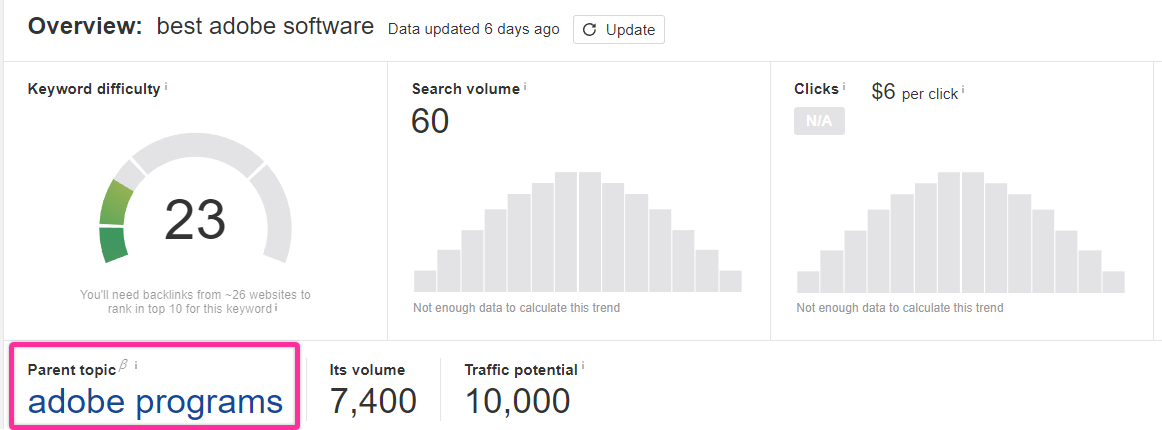
We can also look at the SERPs to see if there are any parent topics.
In Ahref’s SERP analyzer, we can see the top keywords for the ranking pages, which is more or less the same as the parent topic.
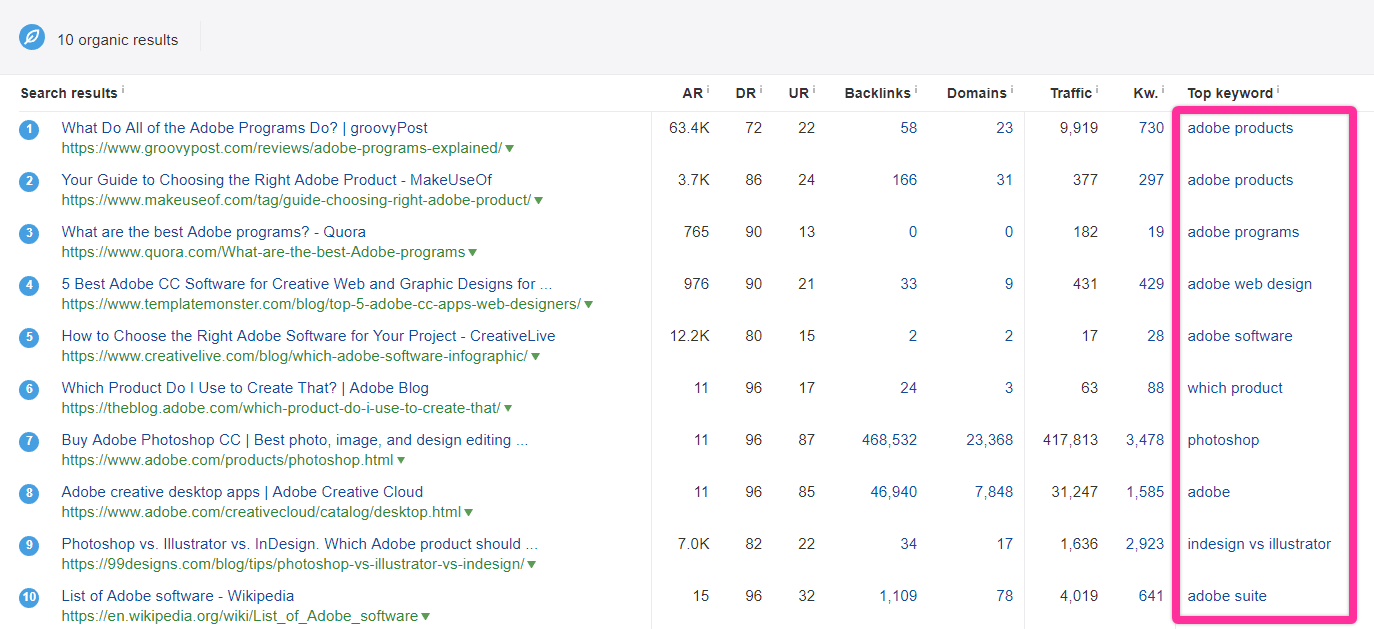
None of these are “best adobe software.”
Because the parent topic is not the topic we’re looking at, the traffic numbers may not line up with what we might get if we rank well for “best adobe software.”
Not necessarily, but maybe.
It’s certainly something to watch out for, and if you see this sort of thing — topics for which the best keywords for successful pages are broader, more competitive keywords — it’s worth doing more digging to figure out if the topic is really as easy as it looks on paper.
Putting it Together: Portrait of a Perfect Keyword (well, topic, really)
Let’s put all this together and talk about what a perfect keyword (and really we’re talking about topics) looks like.
First, a small aside: every topic will have nuance, and with this kind of keyword research, “perfect” will be way more subjective than it might be with simpler tactics. It’s also going to vary heavily based on typical RPMs in a niche and your resources.
These are kind of the benchmarks I set when doing keyword research in most niches, especially if I’m trying to maximize profit per article.
Benchmark #1: Average topical KD ≤ 3
Why KD3? Why not 5? Or 10?
The specific number, of course, is arbitrary. Still, it’s likely lower than you might have guessed.
But remember: with this kind of topical keyword research, we’re trying to maximize traffic potential.
Because most of us are independent site builders, we’re going to have either new sites or sites in the low- to medium-authority range. In this range of authority, the best way to maximize traffic potential is generally to keep KD low.
The Ahrefs KD scale is logarithmic, but on the lower end, one KD point approximately = about one inbound link needed to realistically compete (all else being equal) with other pages in the SERPs.
I’ve found that below KD3, you can generally compete with either no links or solid internal links.
In that topical KD range, the keyword report for a competitor page might look something like this:
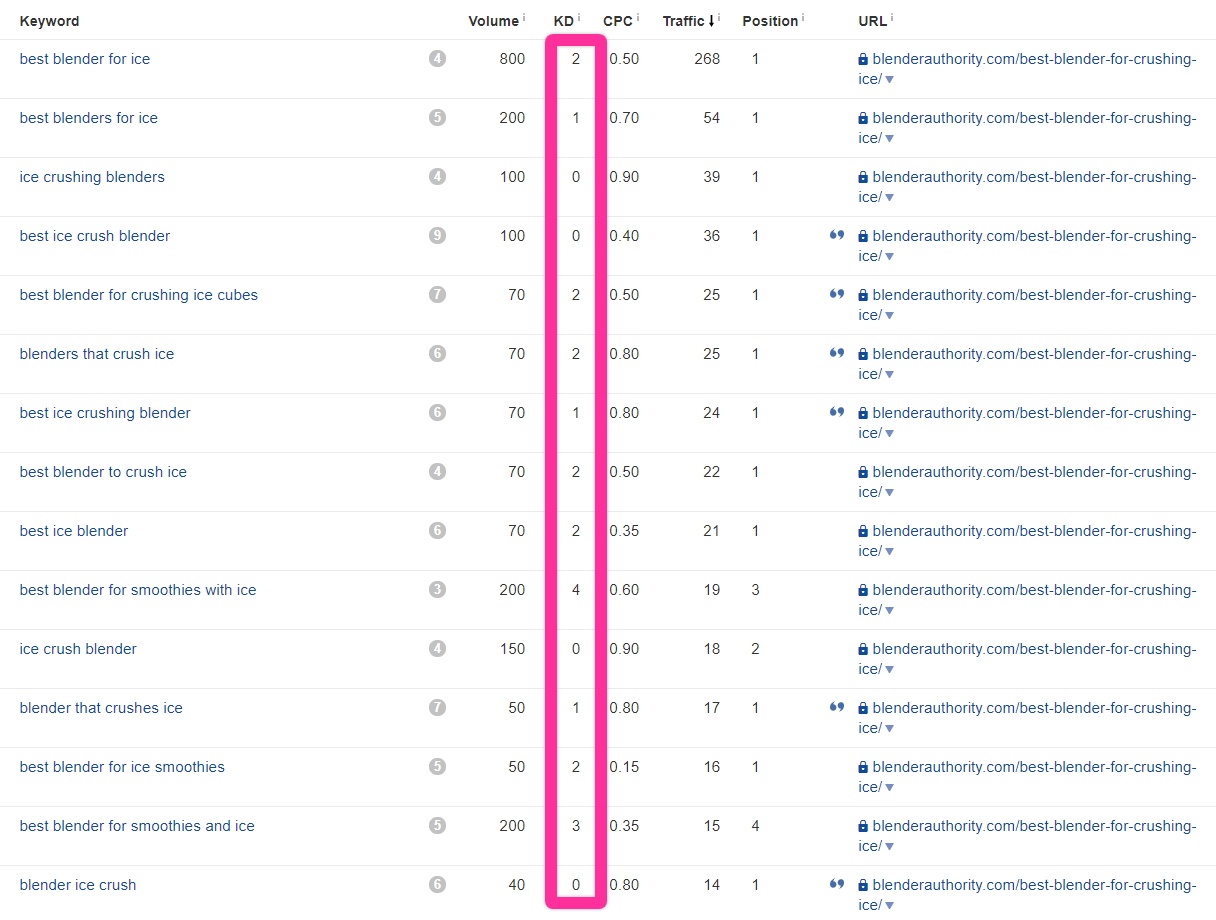
This is the keyword report for a page ranking well for “best blender for ice,” a keyword with a KD of 1.
Notice not all keywords are below KD3.
Just most of them. In fact, it’s going to be pretty rare to see all keywords coming in below KD3. Of the 15 keywords listed for this page, 14 are below our threshold. We can chalk the other one up to an anomaly (which is fine; Google works in mysterious ways, and we don’t need an explanation for everything).
This is more or less exactly what we want to see from a “perfect” topic.
Compare that to something like “best blender under 100,” another good-but-not-perfect topic.

Here, a smaller percentage of the keywords are really easy (10 of 14), and the page ranks much worse for higher-difficulty keywords, which are also much broader.
This is still a good keyword, but I’d have slightly less confidence competing for this one than I would competing for “best blenders for ice.”
So, again, there’s some nuance here, but in general, you want to see that the relevant keywords generating traffic for your competitors have a KD between 1 and 3.
Benchmark #2: Long tail length of at least a few hundred keywords
The perfect keyword should ideally have a long tail length of a few hundred keywords, and the best keywords will have long tails thousands of keywords long.
Remember, too, that we’re looking at our competitors, and we’re looking at trends. If most of our competitors are capturing hundreds of keywords, the topic probably has lots of opportunities to rank.
Let’s return to the SERP for “best blender for ice.”
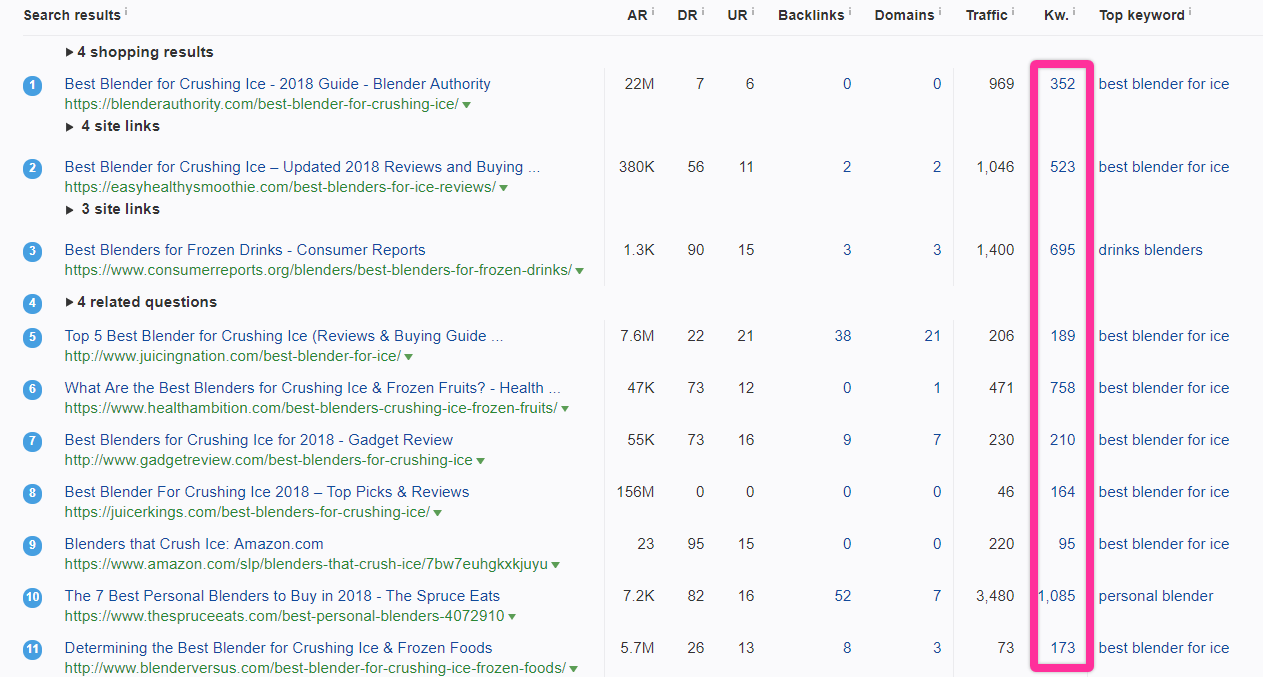
Here, nearly every single page is ranking for hundreds of keywords.
Even more encouraging, pages with 0-2 inbound links are showing up for 300-600 keywords. More encouraging still, the pages ranking for all those keywords are about this relatively narrow topic (there are only a few targeting broader parent topics).
We do see one page here that isn’t capturing as much of the long tail, but it’s an Amazon page, which isn’t a competitor of ours and likely doesn’t have much content on it anyway.
Everything else shows a nice, healthy long tail.
Benchmark #3: Competitor traffic in the thousands
Of all the benchmarks, this is probably going to be the most variable, since the value of traffic can fluctuate so much from site to site.
In general, though, I like to see competitor traffic in the thousands.
At risk of immediately contradicting myself, it’s getting progressively more difficult to find low-competition topics in which that much traffic is floating around. So, when planning content for a whole site, I’ll routinely settle for traffic below 1,000. Traffic in the thousands is just what you’ll see for perfect keywords.
Almost always, though, the bare minimum traffic for me is 200-300.
Let’s keep the “best blender for ice” party going.
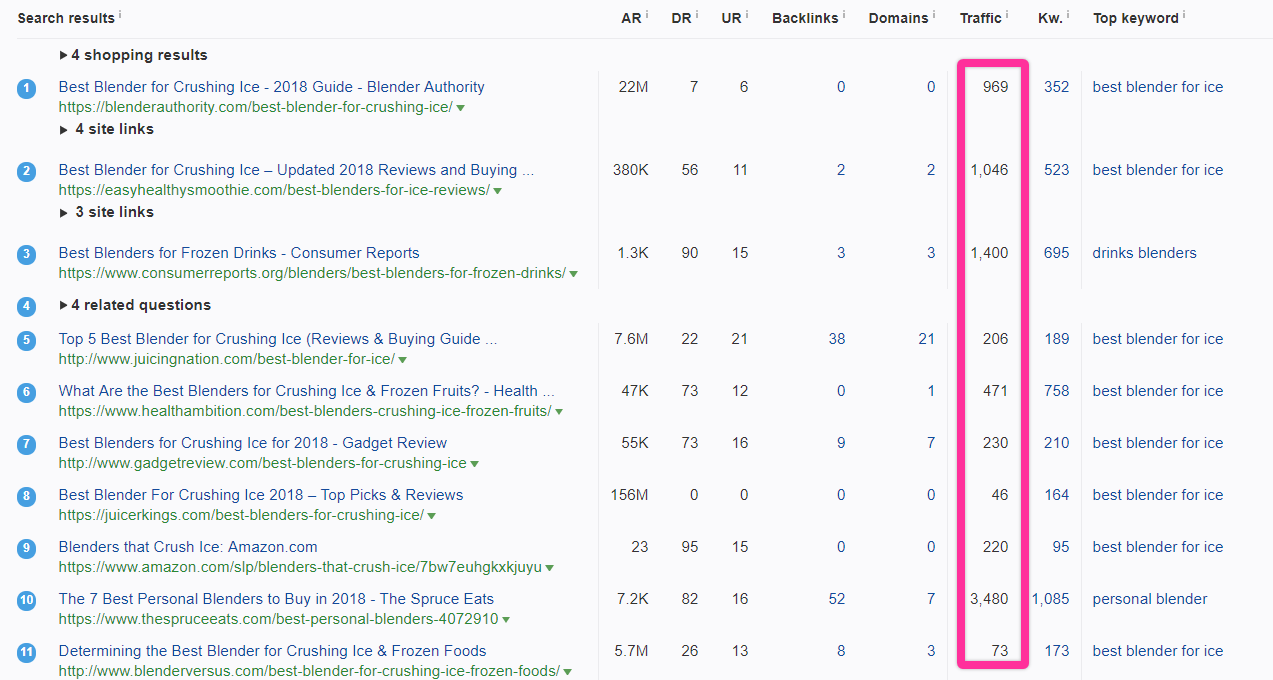
Most of our main competitors here have traffic above 500, and several have traffic in the thousands, both of which are great signs.
Crucially, we do not need to see high traffic for all our competitors.
We just need to see that multiple competitors are capturing good traffic. We’re looking for a signal that the traffic is there and that we can easily compete for it.
It’s also worth looking into pages that rank but have low traffic. For example, in the SERP above, BlenderVersus.com ranks in the top 10 but only generates 73 visits per month. It’s probably not a bad idea just to look at the page and see what’s funky.
For the most part, however, we’re looking for trends of good traffic for pages that rank for this topic.
And our benchmark for that is: at least a few competitors over 1,000 visits/mo (or 300 at minimum).
How to Use New-School Keyword Research to Craft Winning Content
In the context of this new brand of topical keyword research, I don’t think I can overstate the extreme importance of content.
Topical keywords research is useless without content that can capture as much of that topic as possible.
You’ve probably noticed this in the process outlined so far; we’re constantly thinking about why certain content works, which type of content ranks, whether or not we can compete with successful competitor content, and so on.
So, in my view, it’d be silly to publish an article on topical keyword research without including a section on content and how to use content to leverage the power of topical keyword research.
So, if the job of content is to capture as much of the long tail as possible, how do we create content that does that?
First, we have a decision to make.
Narrow Content vs Broad Content
This is one of the eternal content debates.
I get this question perhaps more than any other: Should I target lots of topics on a page (i.e. broad content) or just one (i.e. narrow content)?
It becomes even more difficult when doing topical keyword research because we’re inherently looking to rank for many different keywords.
For example, if you had a kitchen appliance review site, should you write an article about the best blenders for ice, and then another about the best blenders for smoothies? Or should you write a big “The 50 Best Blenders” article with sub-sections for smoothie blenders and ice blenders?
There are advantages and disadvantages to both:
- Narrow content tends to rank easier but generates lower traffic
- Broad content tends to have a tougher time ranking but yields higher traffic
And, honestly, because of its high traffic, broad content can be tempting. Let’s look at three keywords at different levels of broadness — from the most narrow to the broadest.
Here’s the SERP for “best blender under 100,” a relatively narrow topic (assuming you stuck to tightly related keywords).
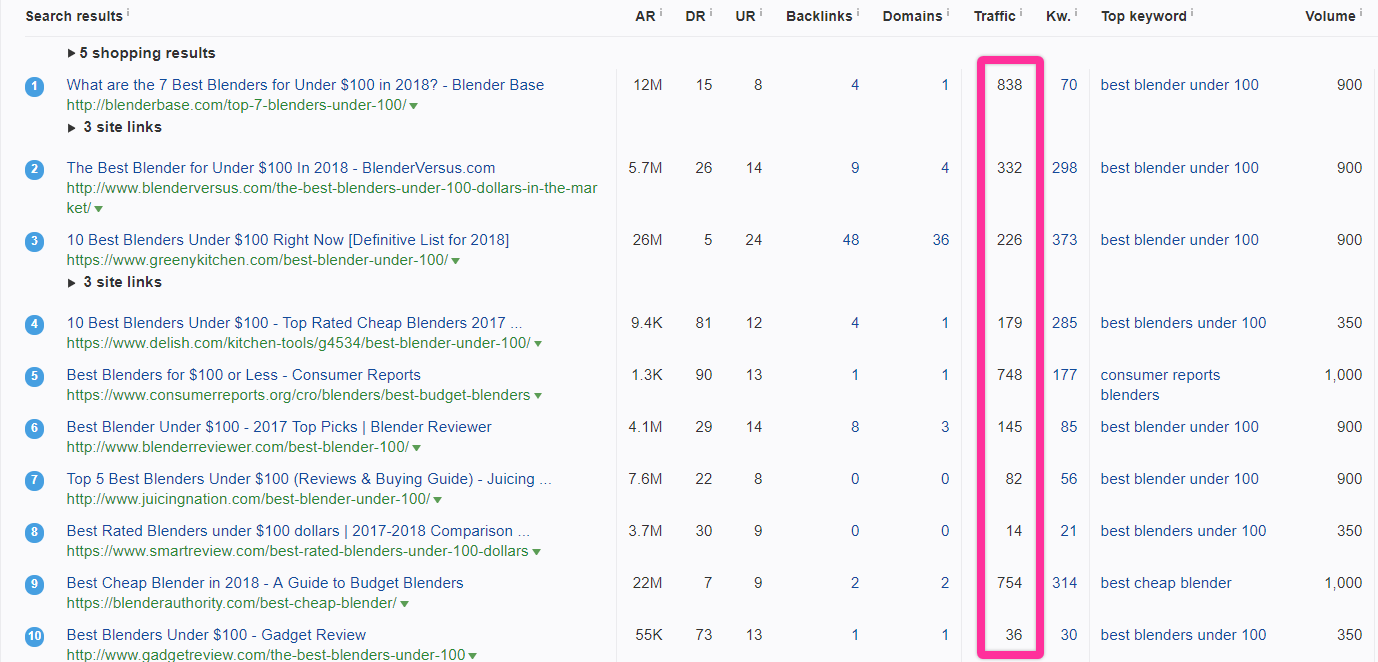
Decent traffic, and there are plenty of results above the threshold we typically like to see for competitor traffic.
But let’s look at the slightly broader “best cheap blenders,” which could include the keyword “best blenders under 100”:
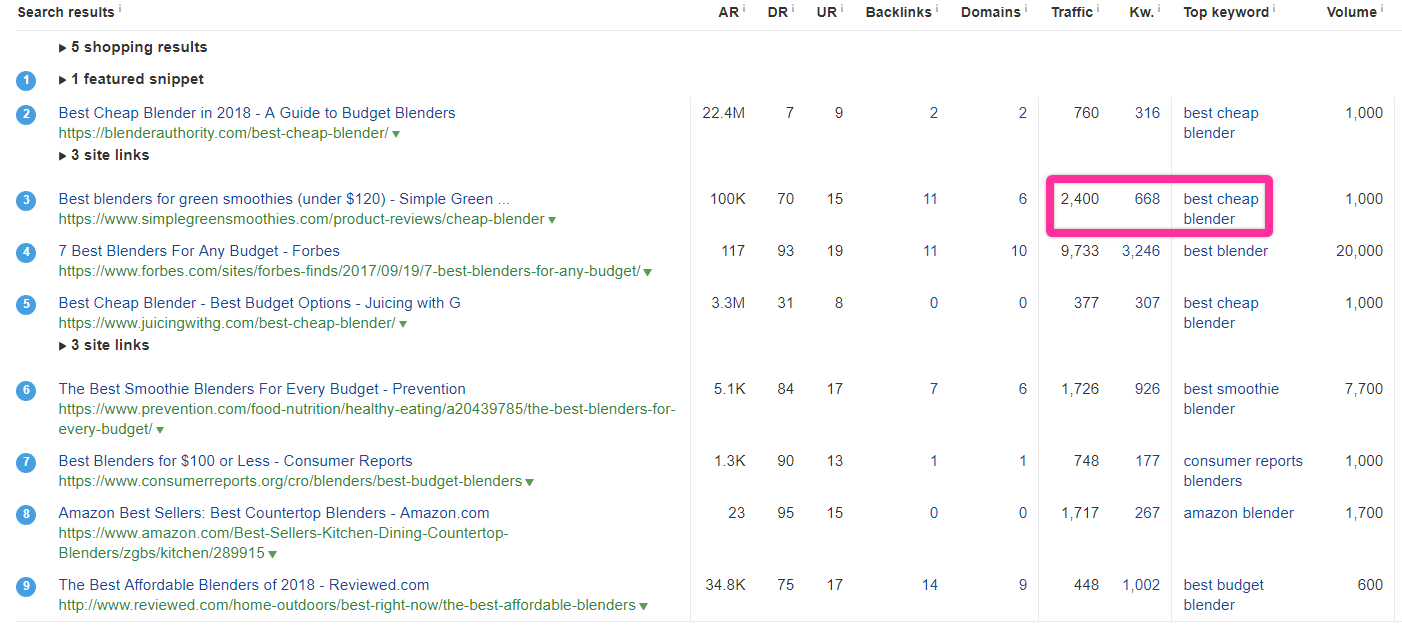
The traffic potential already seems quite a bit higher.
Even though there are a lot more parent topics present, a competitor page ranking primarily for “best cheap blender” is pulling in 2,400 visits per month.
Just below that, though, we get a sneak peek at the traffic of a page ranking for something even broader: the very general “best blender,” which could feasibly include every iteration of any blender keyword:
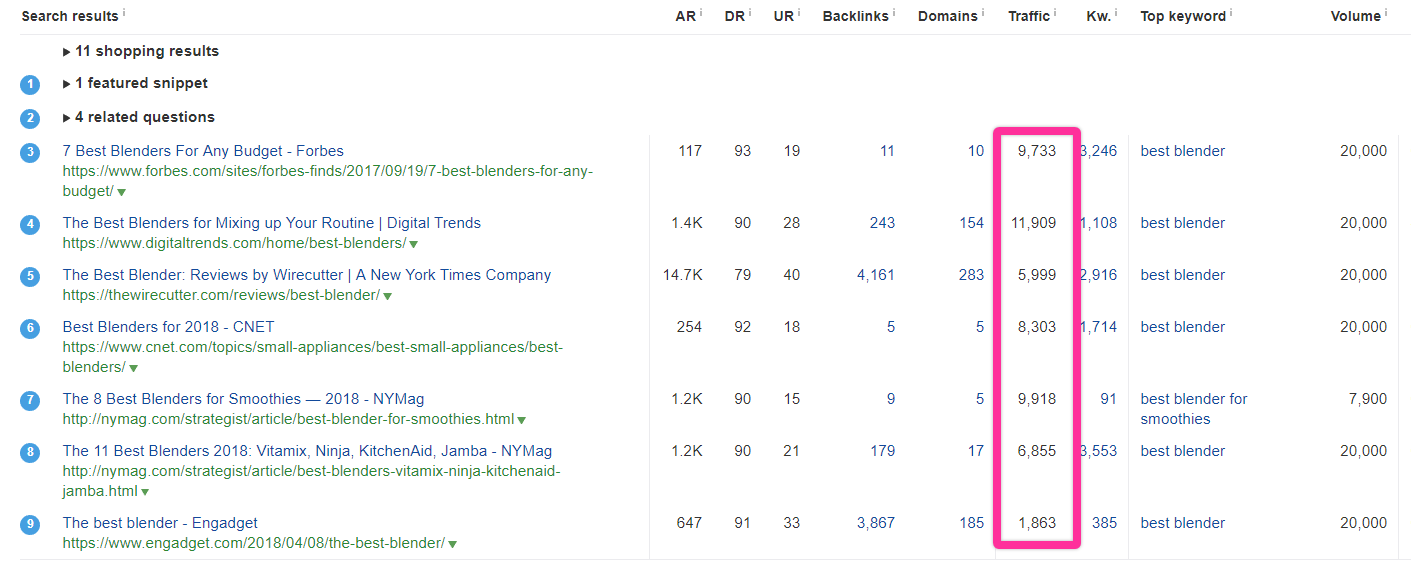
Obviously, that’s a lot of traffic (and money).
And this is typical: the broader a topic gets, the higher the traffic ceiling becomes. So why not go for broad topics instead of narrow ones?
Why write an article about best blenders under $100 instead of a big, fat one about the best blenders overall? I mean, we’re looking for traffic potential, right?
Well, yes, but we’re not just looking for the most possible traffic; we’re looking for the highest traffic potential overall that we can compete for with our resources.
Let’s break that down.
First, we need to frame traffic potential in the context of our resources. Scroll up and look at those last three screenshots again.
You’ll notice that there were fewer inbound links in the first one than the second. And there were a lot more links coming in for the pages ranking for “best blender.” Because broader topics earn more traffic, they attract bigger sites that can spend more money building more links.
In short, it’s more difficult to compete.
Second, we’re building a site, not a single page. So, while we want to maximize traffic per article insofar as our resources permit, we also want to think about maximizing traffic potential for the whole site.
Think of it this way.
We could write one article cataloguing all the best blenders. Based on what we see in the SERPs, if we succeeded, we might expect 7,000 – 12,000 organic visitors per month, while if wrote an article about the best blenders under $100, we might expect 700.
But… what if we wrote 40 articles all targeting topics similar to “best blenders under 100”? If 60% succeeded, we might expect our organic traffic to be around 16,800 — and we likely wouldn’t require nearly as much link building power to get there.
So, I generally recommend going narrower as long as the narrow topics still look like they’d yield good traffic.
Should you always go narrow? No.
If you own a bigger site or have more resources to throw at the marketing power required to compete for bigger topics, it can certainly be worth it.
For most of us, though, narrow is probably the strategy with the lowest risk.
Going narrow also has another massive benefit…
Capturing the Long Tail
This is actually the main benefit of going narrow: if you look at narrow topics, most of the keywords will be very similar, and you’ll rank for many of them naturally just by targeting the “main” variation.
For example, if a narrow topic is a healthy long tail, those keywords tend to be versions of each other.
Here’s an example. It’s the keyword report for a page ranking for “best blenders for ice:”
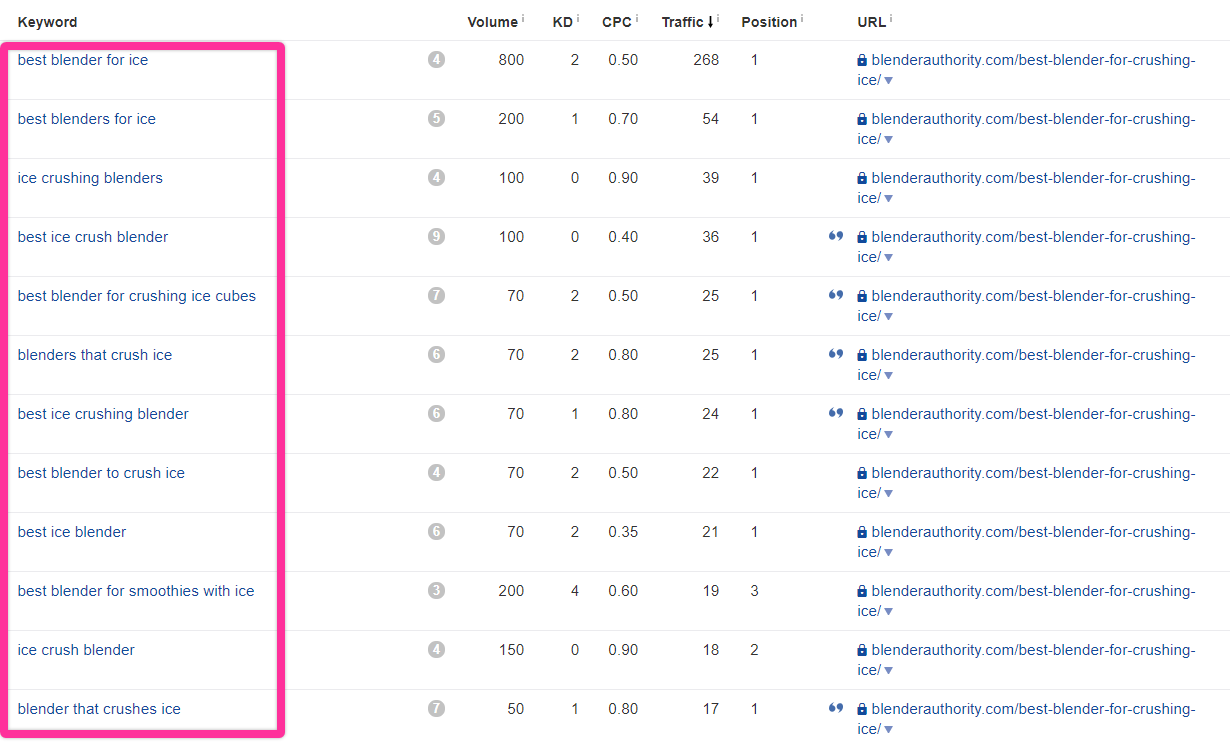
They’re all different iterations of the same idea; people are just using different phrasing when they search for them.
Because they are so similar, we don’t need all of them on a page to capture them. We’ll probably rank for many of them if we rank for one.
Of course, not every competitor page is only going to rank for variations of our main keyword.
And that’s good.
Because to capture the most long tail possible, we want to find all those little, related topics successful pages also rank for and add them to our own article.
To do this most efficiently, we don’t want to just look at one competitor. We want to look at them all.
Let’s look at an example.
We’ll start with our “perfect” topic: “best blenders for ice.”
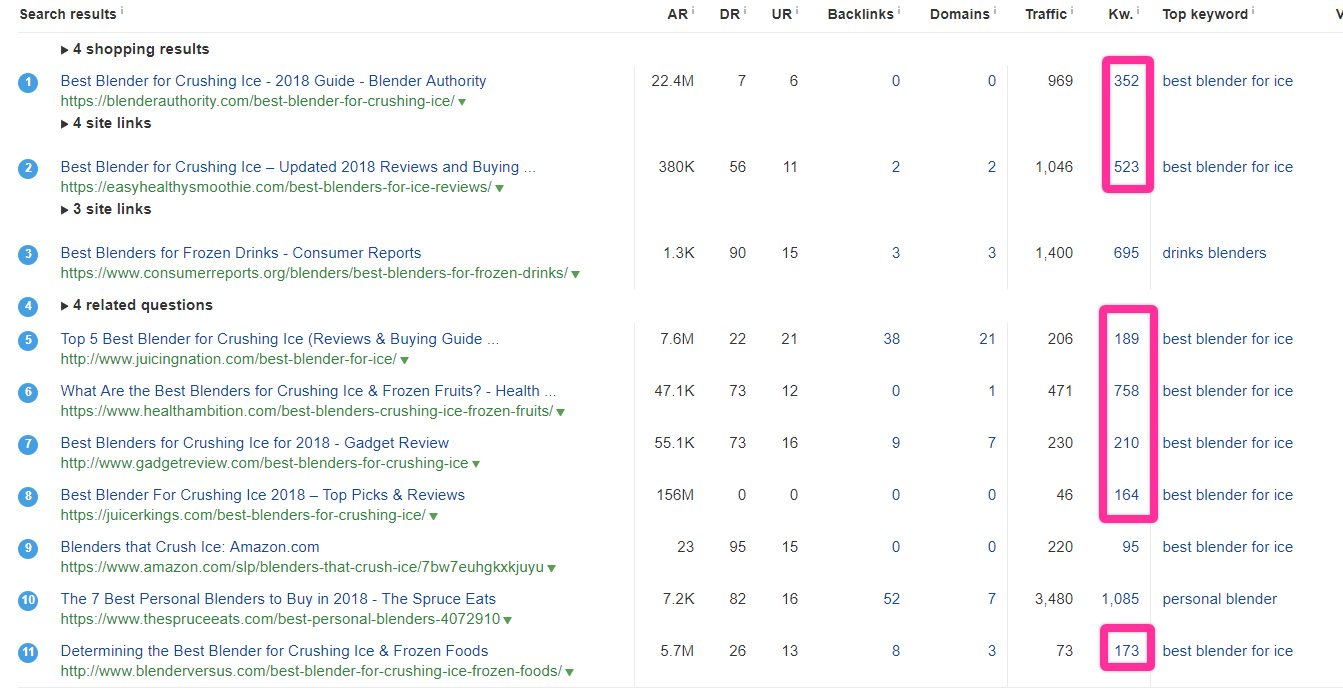
In this SERP, there are seven pages I’d call true competitors — pages that:
- Are writing primarily about this topic
- Are successfully capturing a good chunk of the long tail
- Aren’t too broad
To view the keyword reports, you can just click on the numbers in the keyword column (highlighted above).
Then, we can go through pages that rank for this topic and see which subtopics they also rank for.
A few of them look about the same, so let’s just go through a few competitors that show us interesting stuff. Here’s the first.
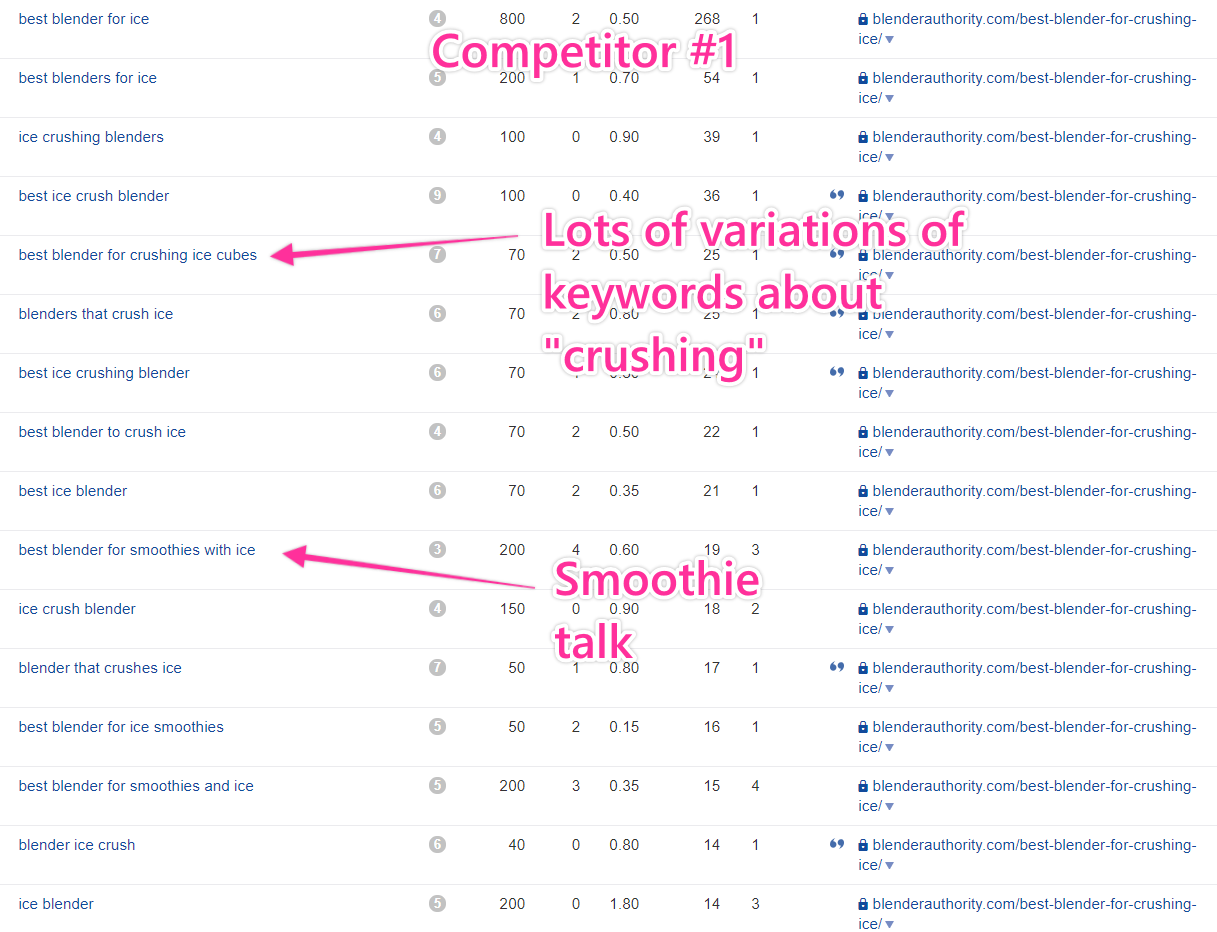
I found similar results in about four of the seven competitors.
What stands out here is:
- I see lots of “ice crushing” keywords
- There’s lots of talk about smoothies
Because each of these has lots of its own variations, we can categorize them as subtopics.
We’re going to talk about what to do with them, but first let’s look at another competitor.
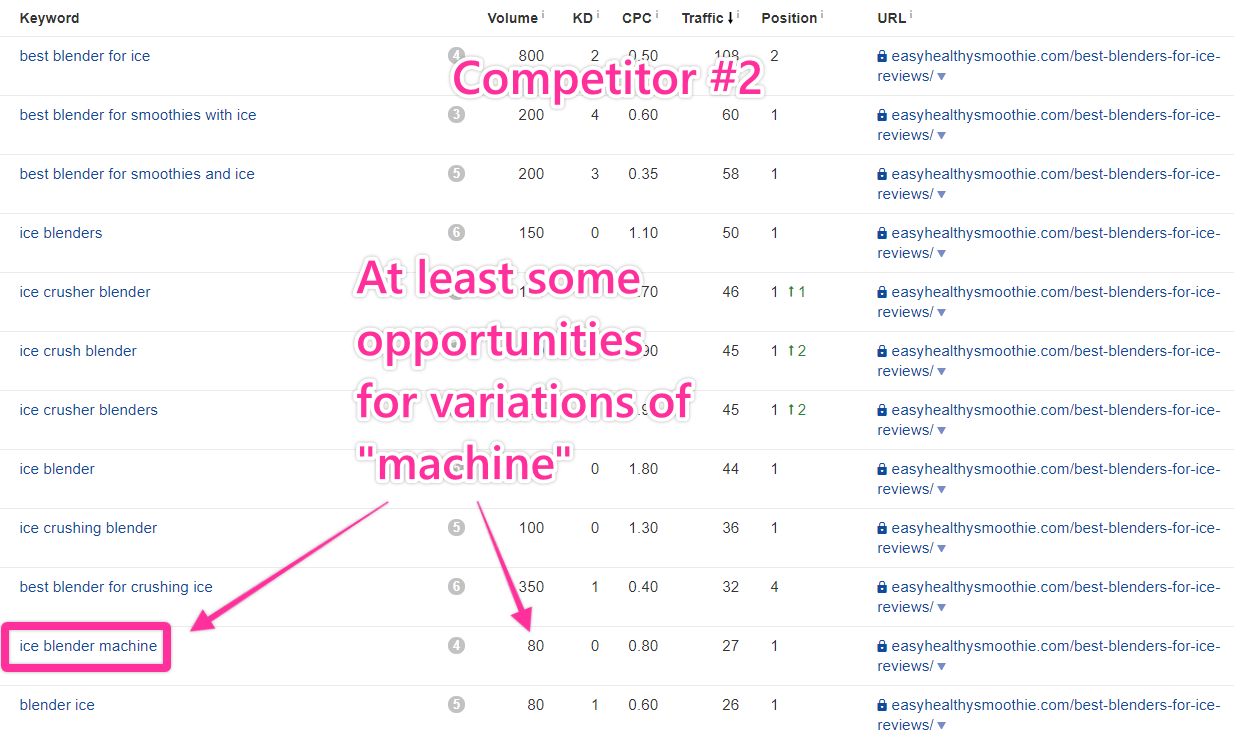
The word “machine” jumped out at me here.
I didn’t see it anywhere else, and a search volume of 80 isn’t insignificant. Still, it was only one, isolated keyword, so I did some light digging to see if there was any opportunity by plugging it into Ahrefs.
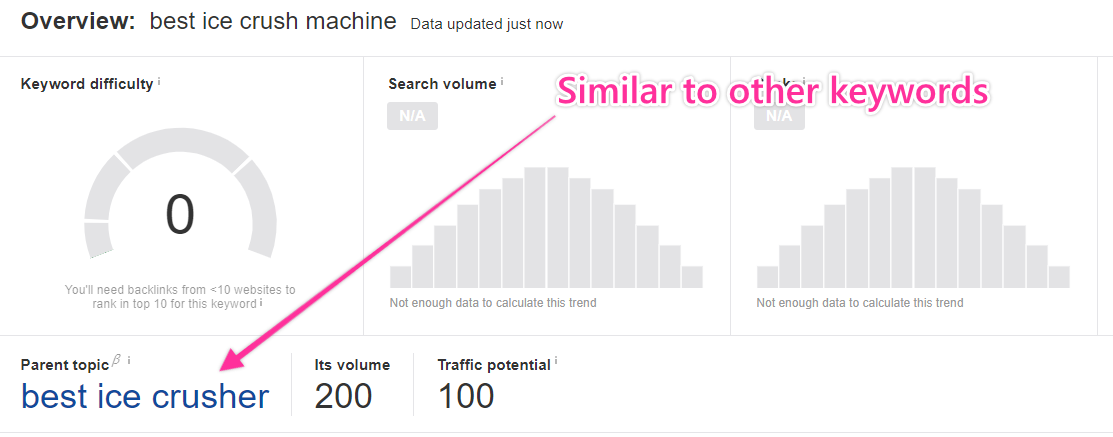
The keyword “best ice crush machine” doesn’t have much of an opportunity itself, but the pages ranking for it are all ranking for variations of “best ice crusher,” which is similar to what we want to write about — but different enough to be its own subtopic. And because one of our competitors is ranking for “machine” keywords, we can safely assume Google finds them related.
I’d tuck this away as another subtopic.
Let’s look at another competitor.
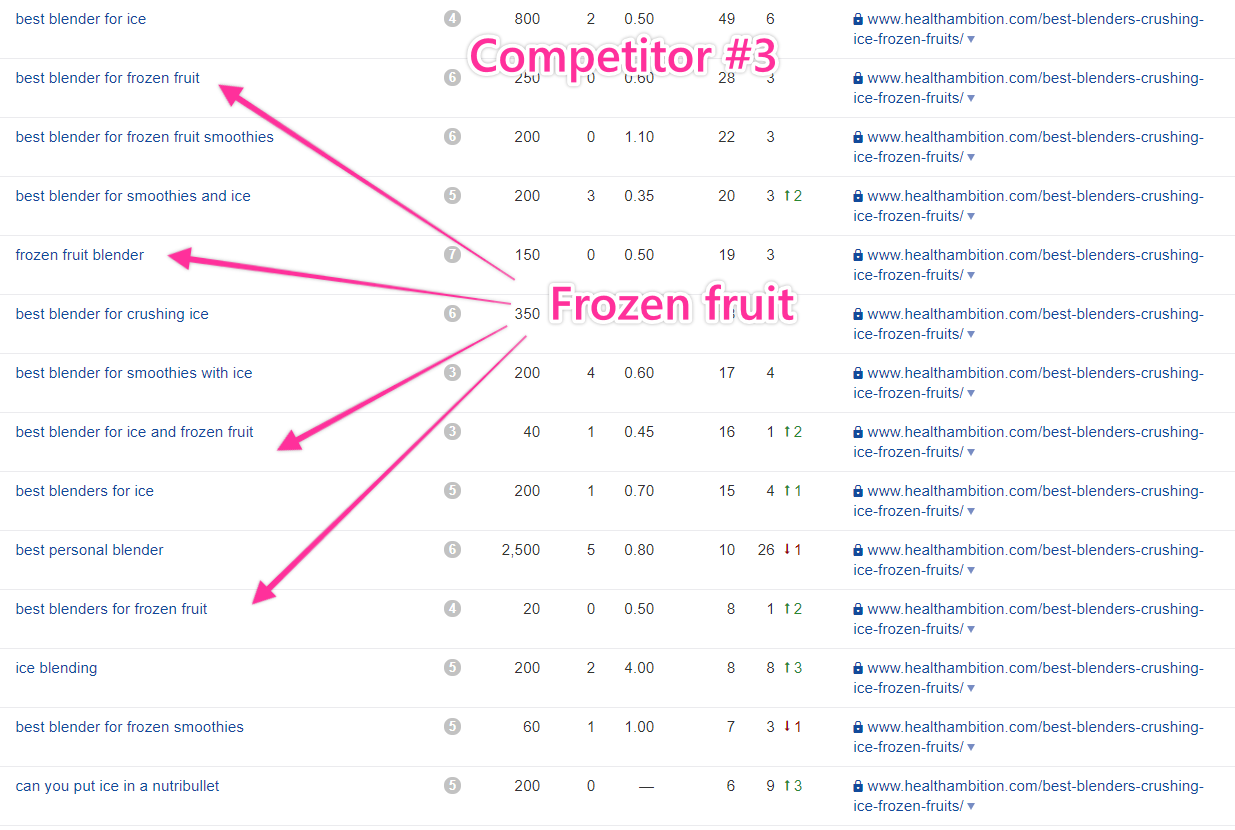
Here, we see frozen fruit mentioned, and those keywords seem to be bringing in roughly as much traffic as ice-related keywords.
Google likely thinks the two are related and is happy to rank them together. Because there are plenty of variations of this one as well, I’ll note it as a subtopic.
One more.
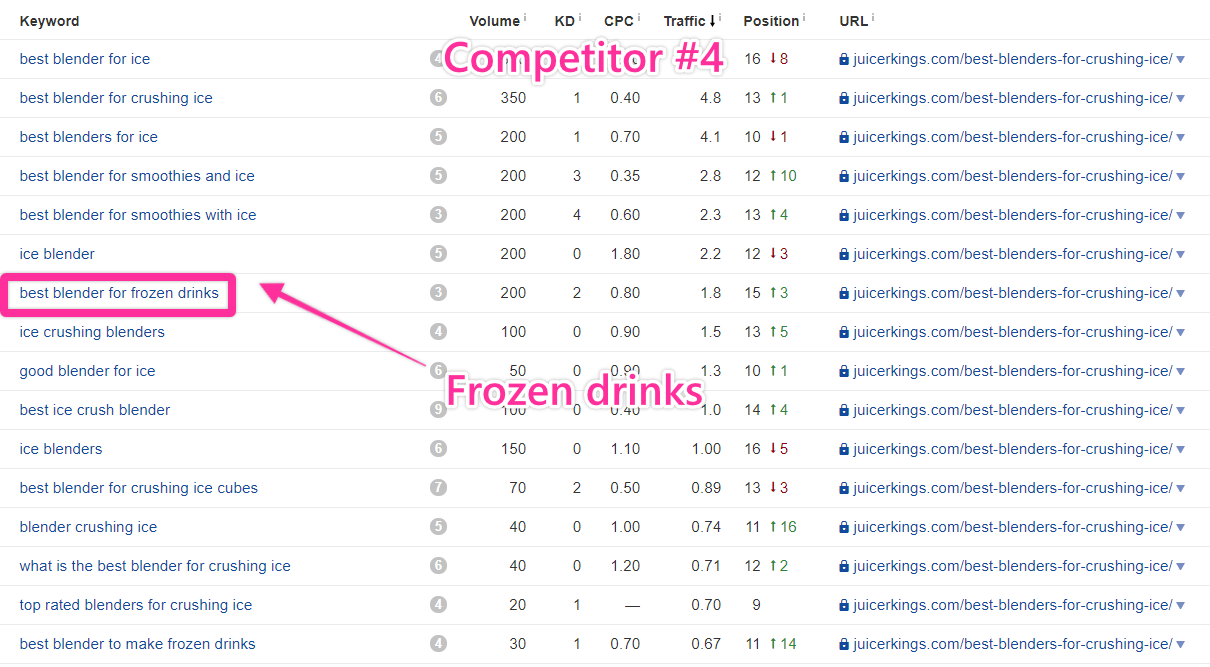
This last one mentions frozen drinks.
This is actually the focus of one of the pages we elected not to look at because we didn’t think it was relevant; however, seeing a page primarily targeting ice-crushing blenders also rank for frozen drink keywords makes me reconsider.
Because the other page ranked for so many frozen drink keywords, I’ll file this one away as a subtopic as well.
So where are we now?
In addition to having a great primary topic, we now have four great subtopics that we know represent significant long-tail opportunity.
In practical terms, our article might be titled “10 of the Best Blenders for Ice: Expert Reviews,” and we might also include subsections like the following:
- Best Blenders for Ice Overall
- Best Ice Crushers
- Best Blenders for Frozen Fruit Smoothies
- Best Blenders for Frozen Drinks
Of course, we’d be sure to do great research and add other sections that include lots of value for our readers.
But by putting all those sections into our article, we can compete for every part of the long tail we see in the SERPs.
Additionally, in each section, we could (very sparingly) sprinkle in variations of that keyword. For example, when writing our section about the best blenders for fruit smoothies, we might sprinkle in “best blender for frozen fruit smoothies” and “frozen smoothie maker,” both of which were variations our competitors were ranking for.
We want to do this conservatively and naturally. No keyword stuff. But plopping in one or two can give our article some added umph.
Long Content Captures More of the Long Tail
I don’t think long content is always a good idea. In fact, I think there’s sometimes a strong business case for short content, especially if you’ve got a high-authority site and want to cover lots of smaller topics
But with the keyword research strategy outlined here, the idea is to invest more into fewer articles, using highly detailed topical keyword research to maximize traffic per page.
This kind of content strategy makes it a lot easier to invest in longer content.
It’s been pretty well documented that long-form content tends to rank better than other kinds of content.
The now-infamous study from SERP IQ showed a strong positive correlation between content length and Google rankings.
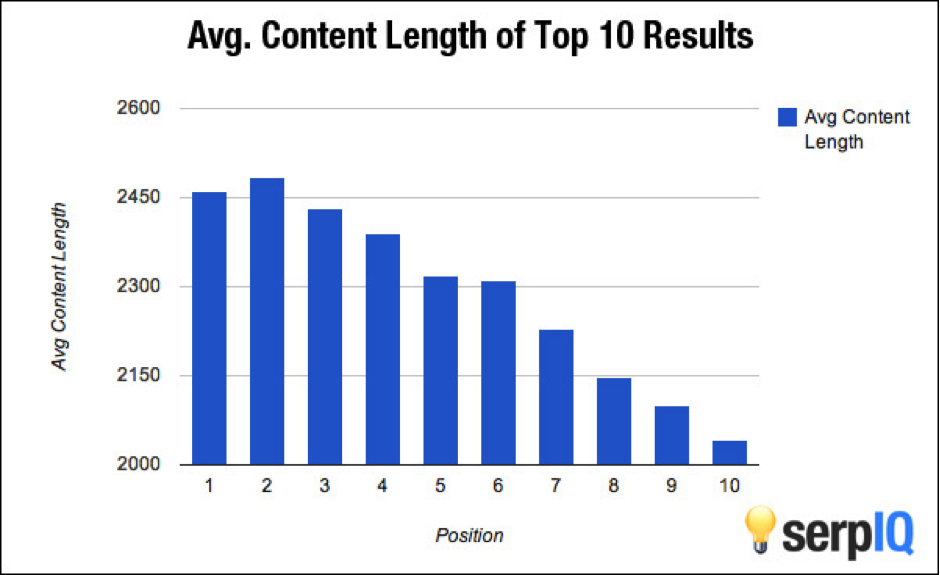
However, I have a suspicion about this data…
I don’t think this correlation comes from longer content causing good rankings (although I do think the two are tangentially related).
I think it’s probably that longer content — simply because it has more words — tends to capture more of the long tail. And because the deeper you get into the long tail of any topic, the weirder and less competitive the keywords become, I think long content probably ranks well for a larger variety of keywords.
And that makes sense, right?
A longer article covering a topic and a few tightly related subtopics would naturally include many more variations of keywords that make up the long tail of the topic as a whole.
We can apply this to our own content.
We don’t even necessarily have to do anything special. We don’t need to quantify an ideal length. We can just generally shoot for longer content where possible.
The Biggest Hurdle: Doing It
This keyword research methodology is powerful.
In fact, I’ve come to believe it’s likely the most powerful tool in my SEO arsenal. I’ve been able to use it to generate very good traffic with very small sites.
But it’s definitely hard.
Not only is it difficult, there’s also a learning curve. It’s far, far more complicated than plugging a few seed keywords in and picking low-KD keywords from a list.
Every topic will look slightly different. There’s much more nuance. It’s a much more advanced skill set.
This methodology is not about generating big lists of keywords and picking a few to write about. It’s about getting elbow-deep into complete content topics… and their subtopics… and even sub-subtopics.
If traditional keyword research takes a couple of hours to do, new school topical keyword research routinely takes several days (and sometimes even longer).
But the payoff really is there.
Not only does content researched and crafted based on good, data-driven topical keyword research tend to generate a lot more traffic; because the traffic per article is higher, you don’t need to invest as much in content overall and you can invest more per article.
So it’s worth it. But, yea, it’s going to take some learning and doing.
So probably the best advice is to get out there, try it yourself, and drop me a comment below if you have any questions.
I’ll keep my eye out!


